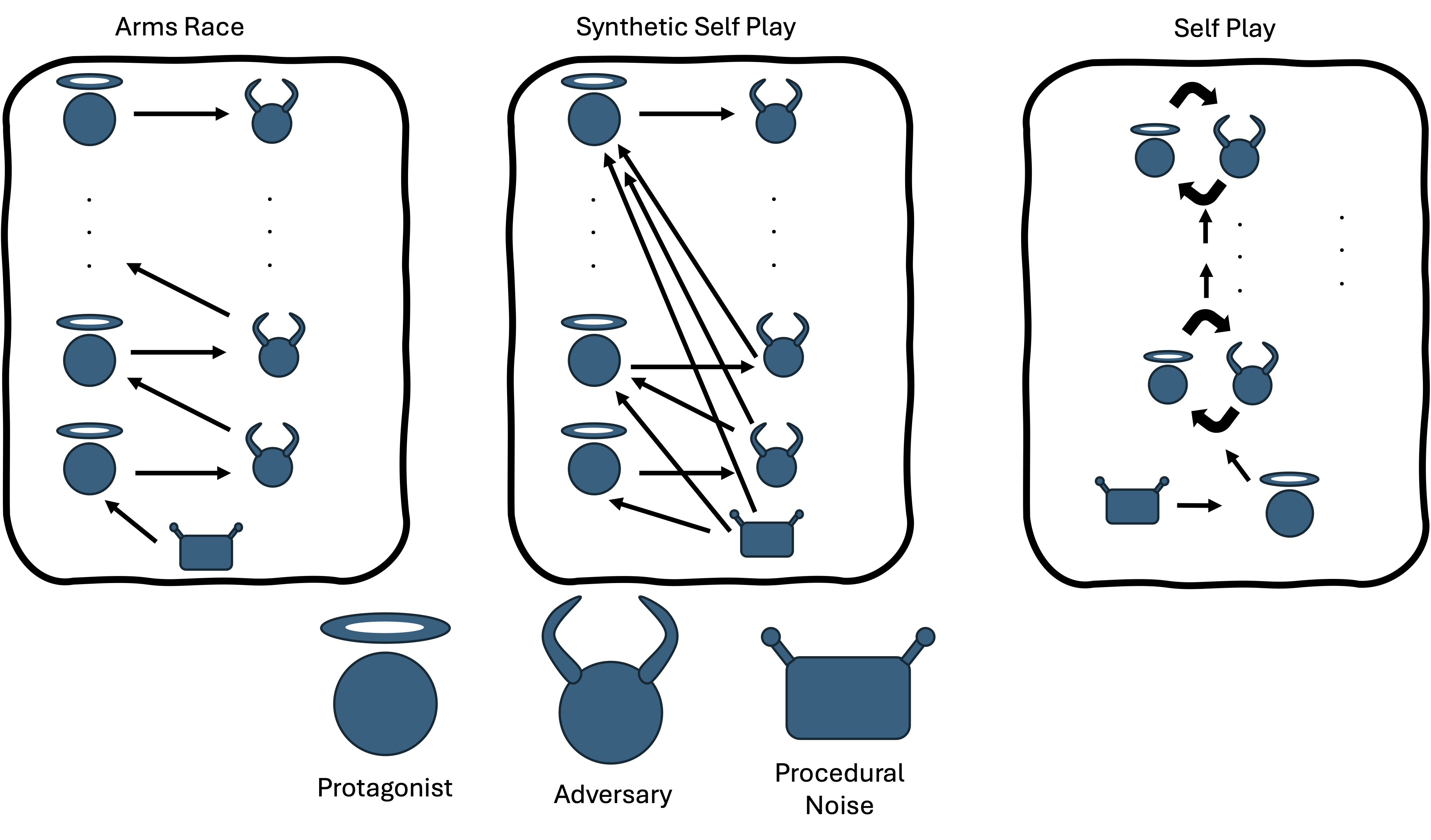
I tested the A parameter across three domains spanning discrete games and continuous control. The results split cleanly along the forgetting prerequisite — and the contrast between RPS and Kuhn Poker is what motivates Forgetting Regret as a predictive metric.
+
Rock-Paper-Scissors — Zoo Helps
Self-play in RPS causes strategy cycling (Rock → Paper → Scissors → Rock) with no convergence to Nash equilibrium. The gauntlet matrix below shows each checkpoint played against every other — the banded structure reveals cycling where early checkpoints periodically beat later ones.

RPS gauntlet matrix (A=0). Each cell shows protagonist checkpoint (row) win rate vs adversary checkpoint (column). The banded red/blue structure shows strategy cycling — later checkpoints periodically lose to earlier ones. This is the signature of catastrophic forgetting in RPS.
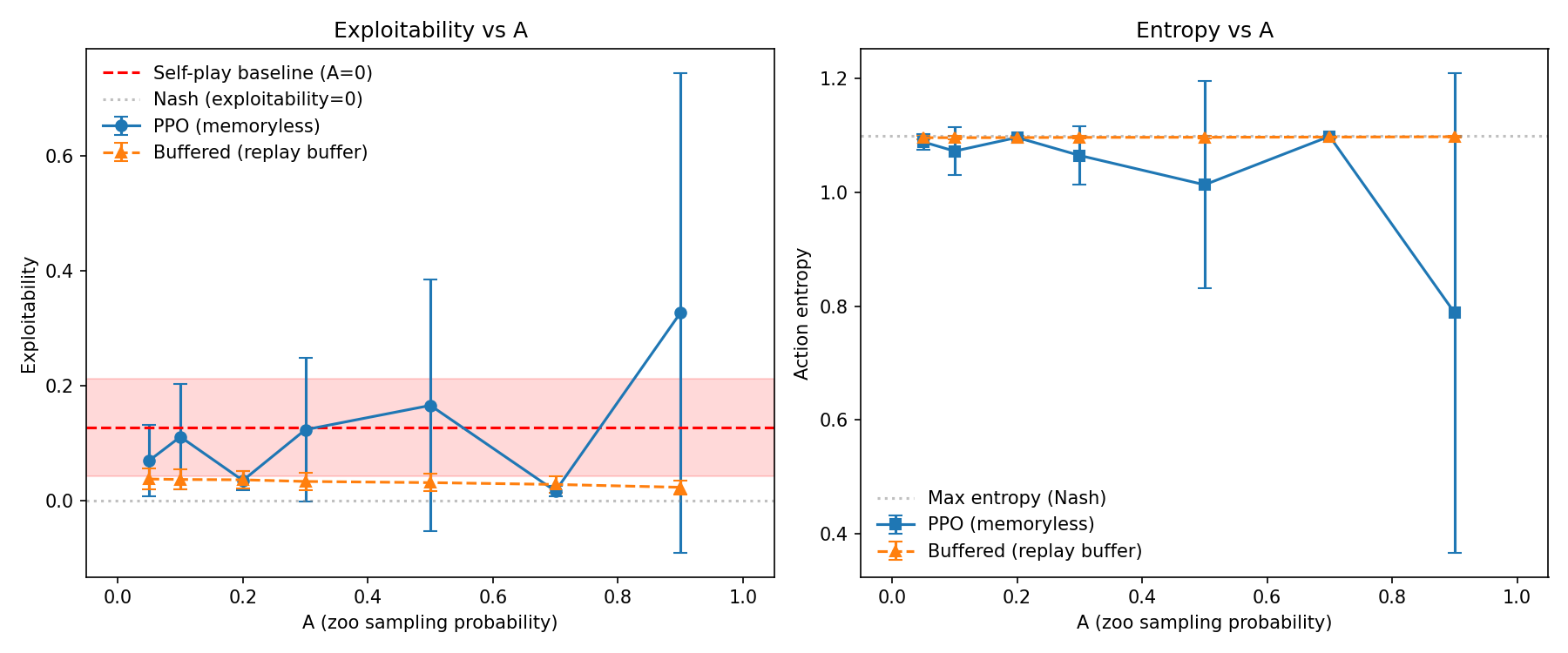
Exploitability vs A. PPO (memoryless, blue) shows high variance and degradation at extreme A values. Buffered (replay buffer, orange) maintains low exploitability across all A values. The replay buffer acts as internal memory, reducing dependence on environmental diversity.
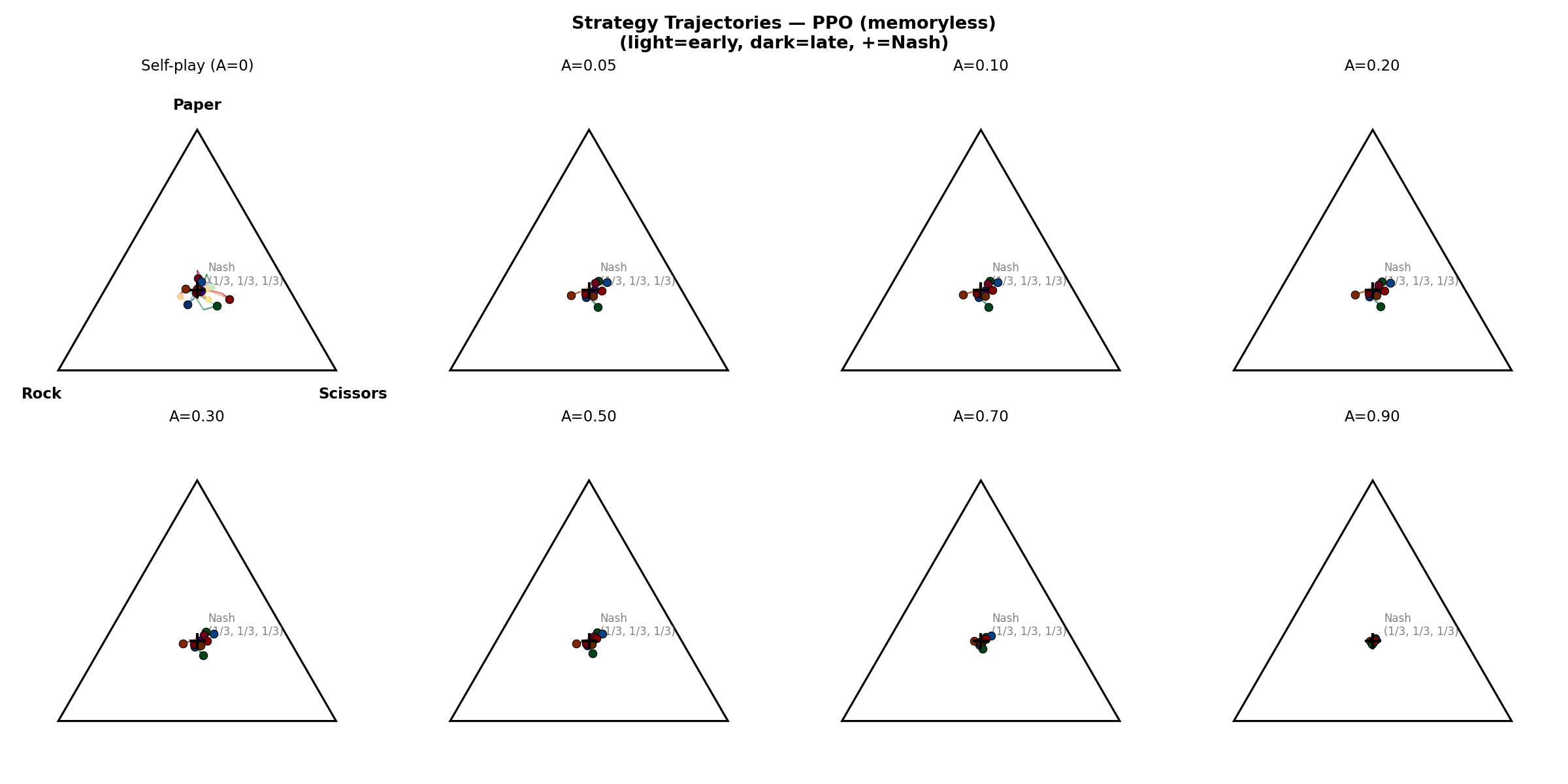
Strategy trajectories on the simplex. At A=0 (self-play), PPO cycles wildly around Nash. As A increases, trajectories tighten around the Nash equilibrium (center). By A=0.7–0.9, strategies converge tightly. Dark dots = later training, + = Nash.
Key finding
PPO's A-curve is steeper than Buffered's — memoryless algorithms need more environmental diversity. At moderate A (0.7–0.8), PPO achieves near-zero exploitability. Buffered stays low regardless, because its replay buffer provides the historical anchor internally.
−
Kuhn Poker — Zoo Hurts (2.6x Worse)
The critical negative result. In Kuhn Poker, there is no catastrophic forgetting — the gauntlet matrix shows a smooth gradient where later checkpoints consistently beat earlier ones. No cycling, no collapse. Contrast this with the banded RPS gauntlet above.
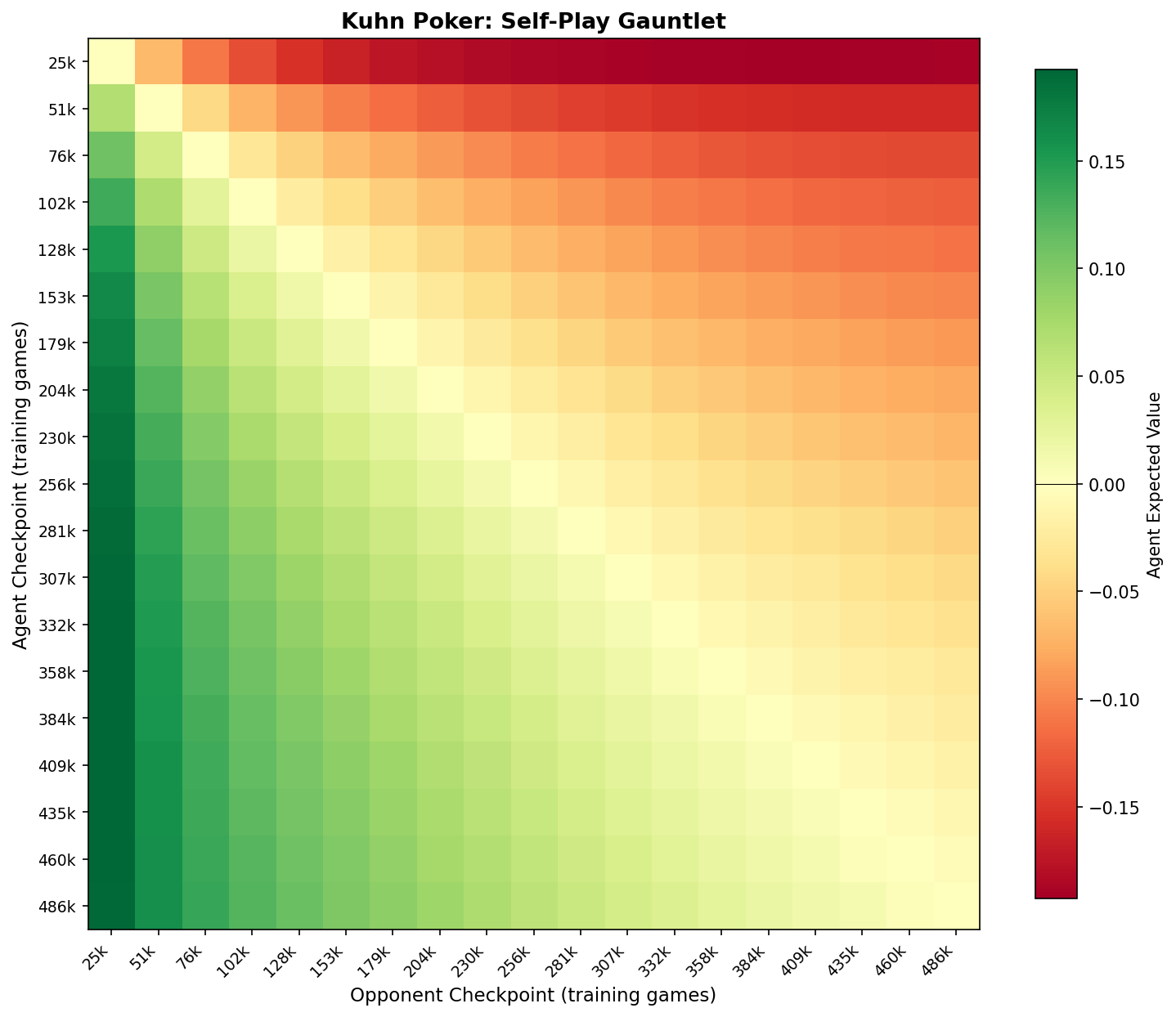
Kuhn Poker gauntlet (A=0, 5-seed average). A smooth gradient from green (lower-left: later agents beat earlier opponents) to red (upper-right: earlier agents lose to later opponents). No banding, no cycling — later checkpoints are monotonically stronger. This is the signature of no catastrophic forgetting.
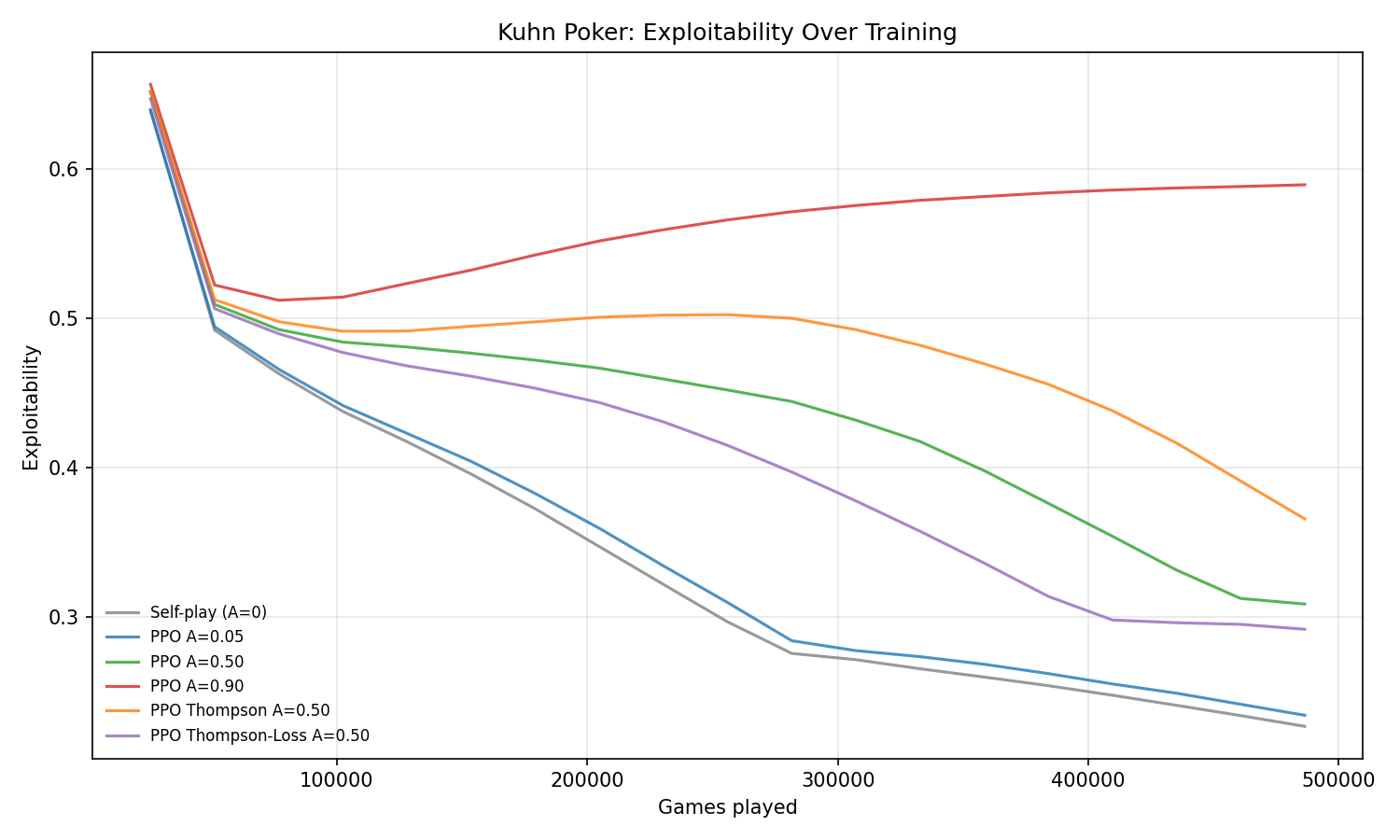
Monotonic convergence. Exploitability decreases steadily for all A values. Self-play (A=0, gray) converges fastest. Higher A values slow convergence by diluting the co-evolutionary signal with weak historical opponents.
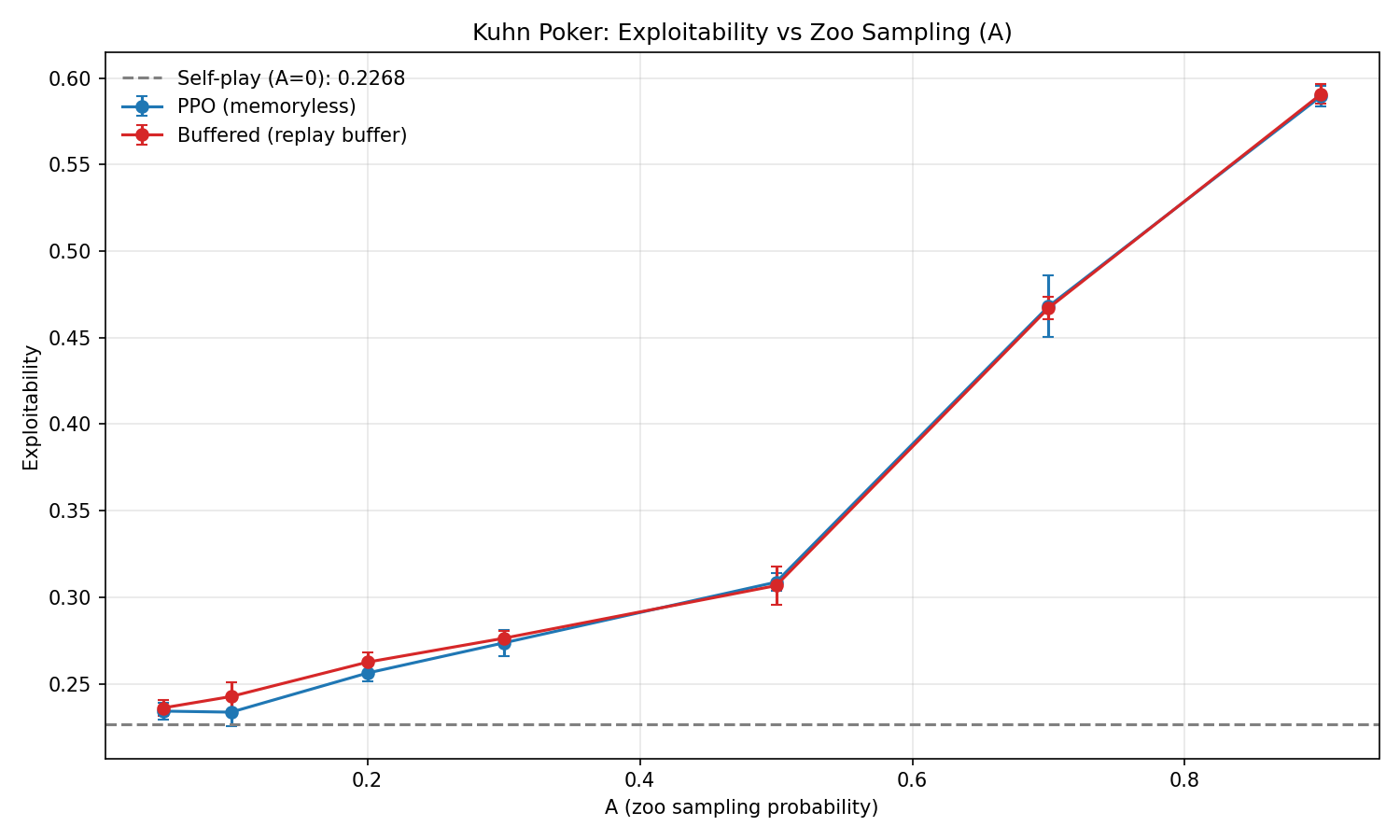
Kuhn Poker A-curve. Exploitability rises monotonically with A for both PPO and Buffered. A=0 (self-play) achieves the lowest exploitability. At A=0.9, exploitability nearly triples. PPO and Buffered are identical — memory capacity is irrelevant when forgetting isn't the bottleneck.
Every RPS finding inverts
Where RPS showed PPO steeper than Buffered (memory matters), Kuhn Poker shows them identical (memory irrelevant). Where RPS showed optimal A > 0, Kuhn Poker shows A* = 0. The prerequisite — catastrophic forgetting — determines which regime you're in.
This contrast motivates Forgetting Regret
RPS has forgetting and zoo helps. Kuhn Poker has no forgetting and zoo hurts. If we could measure forgetting from a single baseline run, we could predict whether zoo sampling is worth trying — without running an expensive A-sweep. That metric is Forgetting Regret (FR).
−
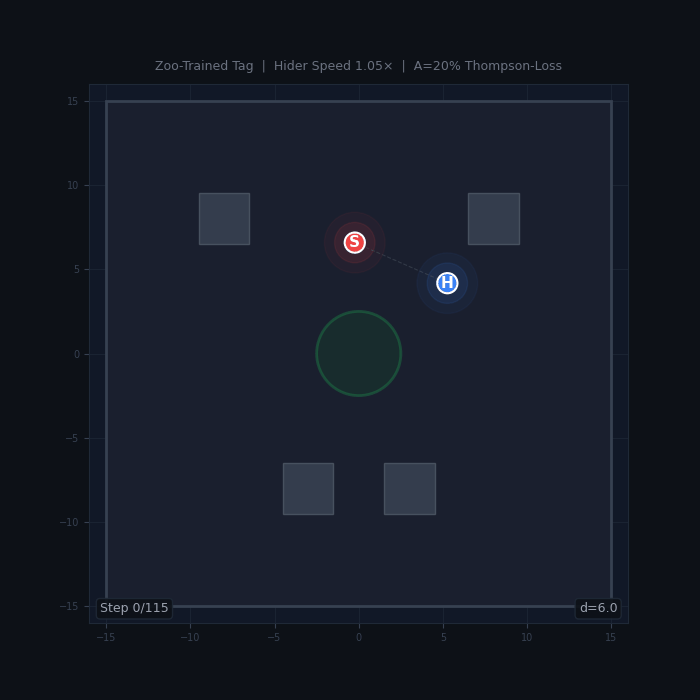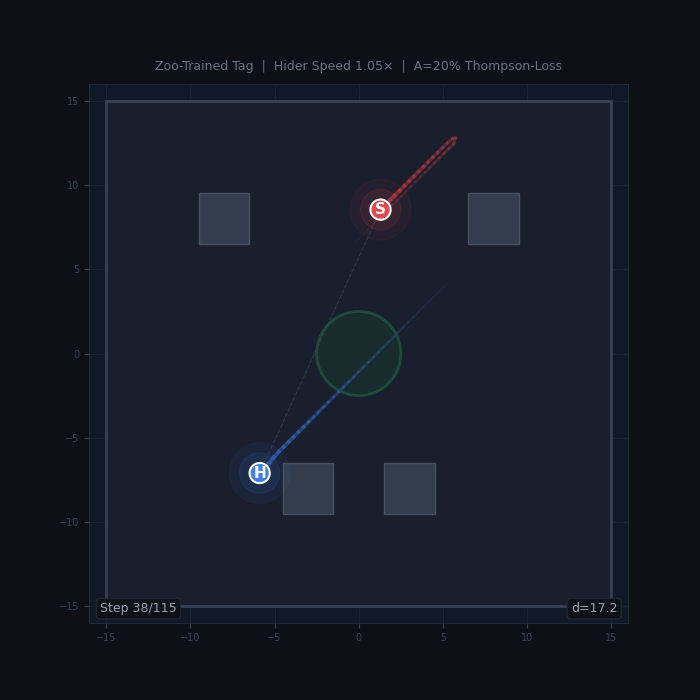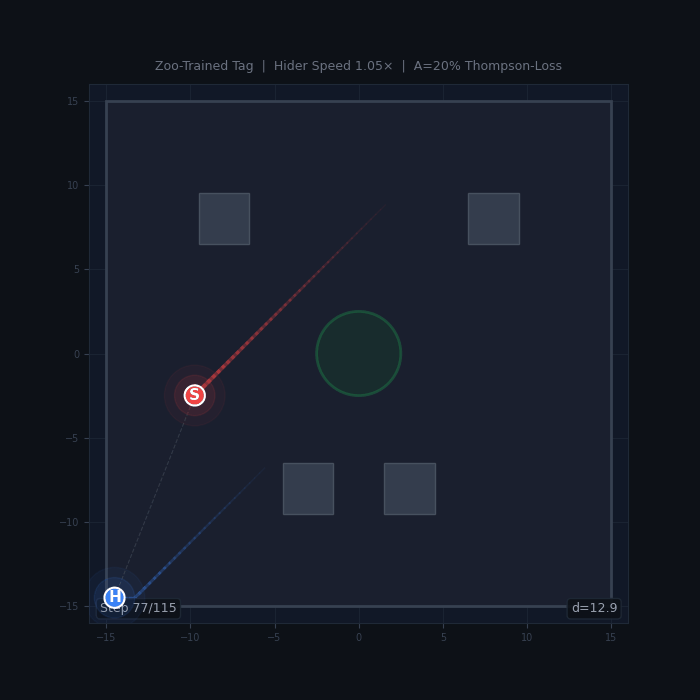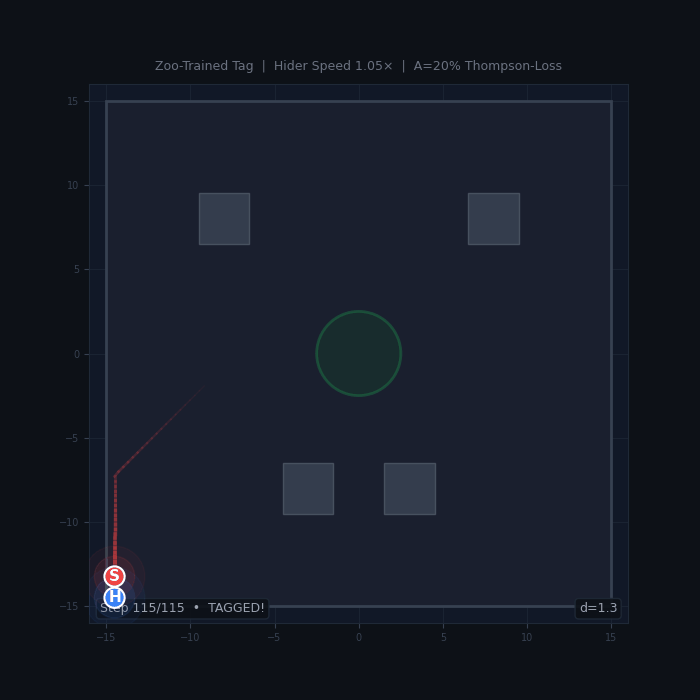
Tag (HPO study, 150 runs) — Zoo Has No Effect
A continuous-action tag game where a seeker chases a hider in a bounded arena with obstacles. An initial study with default hyperparameters (2,800 runs, 20 configurations) suggested zoo sampling helped in 18/20 configs. A follow-up HPO study with Optuna-optimized hyperparameters (150 runs: 5 reward presets × 2 algorithms × 5 A values × 3 seeds, plus a 2,500-matchup cross-evaluation gauntlet) overturned this result.
Tag gameplay. The seeker (red) chases the hider (blue) in a bounded arena with obstacles and a central safe zone.
A has no effect on agent strength or forgetting
With Optuna-tuned hyperparameters, pure self-play (A=0) produces agents just as strong as full zoo training (A=1) for both PPO and SAC. The initial positive result was a confound: default hyperparameters held back PPO, making zoo sampling appear helpful when it was actually compensating for bad optimization.
Algorithm choice is the real signal
SAC dominates PPO 95-to-2 in cross-algorithm play, regardless of A value. SAC agents appear to "fail" during training (15% seeker win rate, oscillating) but produce dramatically stronger transferable policies. Training SWR is a poor proxy for agent quality.
Massive forgetting, but zoo doesn't help
SAC exhibits FR=0.357 (100% of runs show substantial forgetting), yet zoo sampling has no effect. Self-play oscillation in SAC already creates sufficient behavioral diversity naturally — the zoo's historical anchor is redundant.