Plant-level wind farm control can increase fleet power production through coordinated yaw steering, but is vulnerable to sensor errors—whether from instrument drift or adversarial tampering. Standard robustness testing uses procedural noise (independent Gaussian draws with a fixed episodic bias), which systematically misses correlated, temporally structured failure modes. We train an RL adversary to inject worst-case sensor corruption, then compare three co-training paradigms—Arms Race, Synthetic Self-Play (SSP), and Self-Play—for hardening the controller against these attacks. The Arms Race controller reduces worst-case performance from −39% power loss to +7.9% power gain relative to baseline, while the procedurally-trained controller is completely confounded.
Problem Setup
A protagonist (yaw controller) and adversary (sensor corruptor) interact in a two-turbine wind farm simulated with the Dynamic Wake Meandering model. The adversary observes true state and injects bounded, time-varying measurement biases into wind speed, direction, yaw, and power channels. The protagonist observes only the corrupted signals. The adversary's reward is the negative of the protagonist's, making this a zero-sum game.
Critically, the adversary's perturbations are temporally correlated—it learns to time sensor drift to exploit wake advection delays, coordinating multi-channel attacks that procedural noise cannot produce. The research question: does training through interaction with an adversary agent yield greater protagonist robustness than training with procedurally generated noise?
Wind farm flow field at hub height during adversarial attack. The upstream turbine's yaw controller has been confounded to sense an incorrect wind direction, misaligning the wake.
Three Co-Training Paradigms
Co-training a controller and adversary risks catastrophic forgetting: each generation overfits to its current opponent and loses performance on prior threats or clean conditions. We compare three approaches to managing this instability.
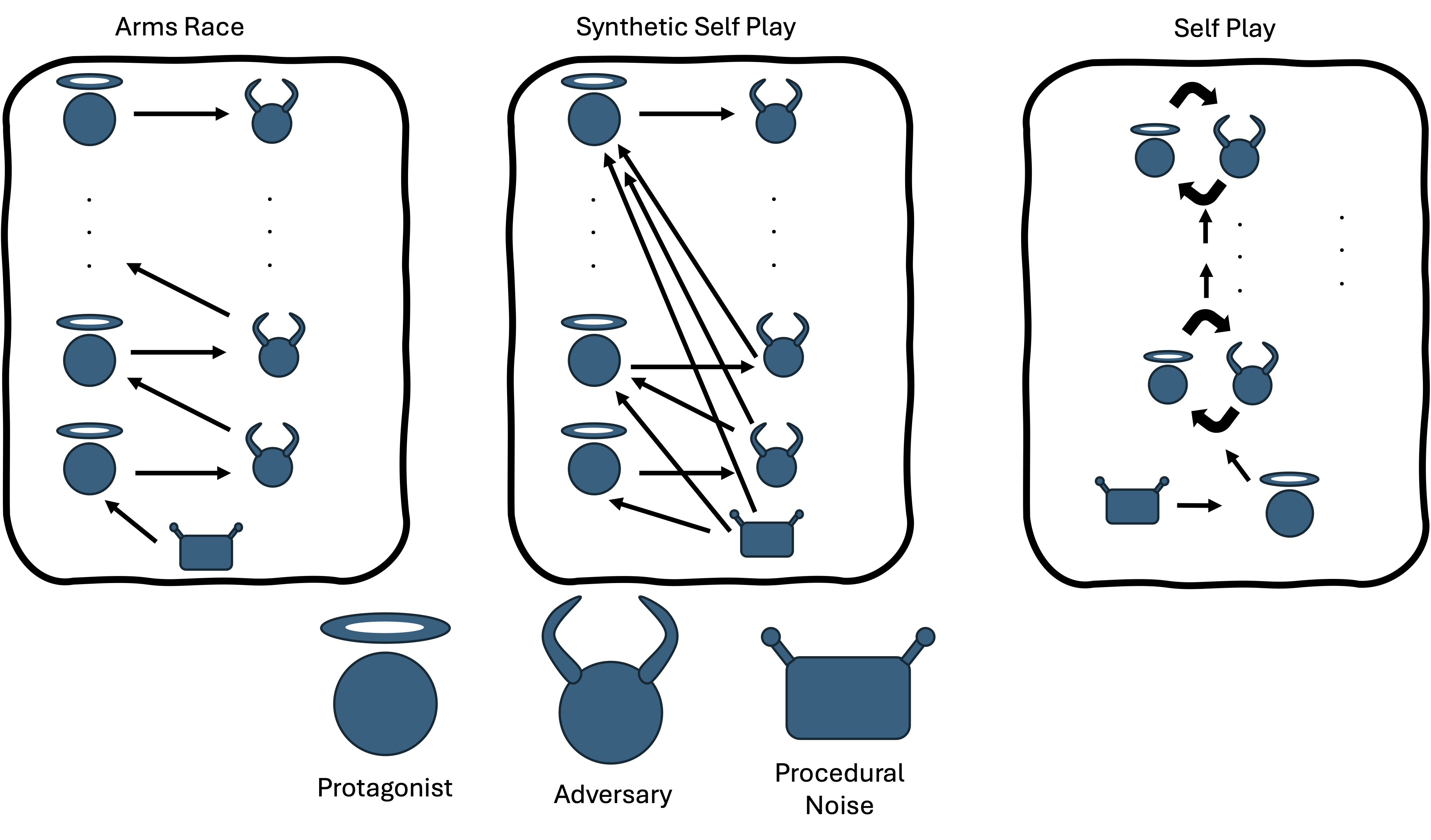
Left: Arms Race. Center: Synthetic Self-Play (SSP). Right: Self-Play.
Arms Race
Sequential iteration: protagonist n trains exclusively against adversary n−1. Each generation discards all prior opponents. Prone to forgetting but recovers in later iterations.
Synthetic Self-Play
Protagonist N trains against a zoo of all prior adversaries {0, …, N−1} plus procedural noise, sampled uniformly each episode. Intended to mitigate forgetting via curriculum diversity.
Self-Play
Protagonist and adversary co-evolve simultaneously in a zero-sum PettingZoo game with independent gradient updates. Produces the strongest adversaries but the protagonist is dominated.
Training Dynamics
Each method was run for 10 iterations of 250k timesteps. The summary plots below compare six metrics across training iterations: protagonist vs. its own adversary (diagonal of the gauntlet matrix), clean-environment performance, mean robustness across all adversaries, and the corresponding adversary-side metrics.

Six summary views comparing Arms Race, SSP, and Self-Play across training iterations. The Arms Race protagonist dips at iteration 4 (forgetting) then recovers. SSP forgets clean-environment operation after iteration 8. Self-Play converges to adversary-dominated equilibrium.
Key observations from these curves:
- Self-Play converges to a state where the adversary dominates—the protagonist never recovers meaningful positive reward.
- SSP yields the highest clean-environment performance for most iterations but catastrophically forgets clean operation after iteration 8.
- Arms Race shows a pronounced forgetting dip at iteration 4, then re-learns robust behaviors in subsequent iterations. The final protagonist achieves the highest mean robustness across all adversary types.
- The Arms Race and SSP adversaries suffer from their own forgetting, drifting to states that do not confound the PyWake expert agent as severely as Self-Play adversaries do.
Arms Race Gauntlet
The evaluation matrix shows mean power gain for each protagonist (row) against each adversary and baseline condition (column), averaged over five standardized inflow episodes. Forgetting is visible at iterations 6 and 9, where protagonists lose performance in clean/procedural conditions. The PyWake expert excels in clean conditions but is confounded by most trained adversaries.

Arms Race gauntlet. Each cell reports mean power gain over baseline (± standard error) across five inflow conditions. Brighter colors indicate higher performance.
Cross-Method Evaluation
The strongest protagonist from each method (selected by maximum mean performance across all adversaries) is pitted against the strongest adversary from each method, plus procedural noise and clean conditions. This is the definitive comparison.

Cross-method evaluation. Best protagonists (rows) vs. best adversaries (columns) across five standard inflow conditions. Arms Race Prot 7 maintains positive reward across all adversary types.
| Controller | Worst-case | Clean | Notes |
|---|---|---|---|
| Arms Race Prot 7 | +7.9% | +32.7% | Robust across all adversary types |
| SSP Prot 9 | −31.9% | +49.7% | Inconsistent; fails against AR adversary |
| Procedural | −39.0% | +48.1% | Completely confounded by SP adversary |
Failure vs. Robustness Under Attack
To understand what robustness looks like in practice, we compare the procedurally-trained controller and the Arms Race controller under identical attack (Self-Play Adversary #6). The adversary spoofs the downstream turbine's power sensor to read zero, confounding the procedural controller into extreme yaw commands. The Arms Race controller maintains stable operation under the same corruption.

Procedural vs. Self-Play Adv #6
−40.2% power (failure)
Controller calls for extreme yaw angles that would likely damage real hardware.

AR Prot #7 vs. Self-Play Adv #6
+15.8% power (robust)
Despite identical sensor corruption, the controller maintains stable yaw commands.
Left columns: upstream turbine. Right columns: downstream turbine. Red dashed: true value. Black solid: sensed (corrupted). Grey bands: maximum allowable error. Rows: wind direction, wind speed, power, yaw.
Discussion
The Arms Race paradigm produces the most robust protagonist and the most formidable adversary in cross-method evaluation. This is somewhat counterintuitive—sequential replacement (discarding prior opponents) outperforms the zoo-based approach that was designed to mitigate forgetting. The likely explanation: the Arms Race creates escalating pressure that forces genuine robustness, while SSP dilutes the curriculum with weak early adversaries.
Limitations. These results are from a single training seed on a two-turbine farm with laminar inflow. There is substantial seed-to-seed variability in RL training, and the relative method rankings may shift with different random seeds or at larger scale. The two-turbine case was chosen to make systematic comparison across three paradigms tractable; scaling to realistic farm sizes is future work. Additionally, the absence of turbulence simplifies the problem—real-world robustness may require additional domain randomization.
Connection to broader adversarial robustness. The dynamics here parallel findings in LLM red-teaming: adversarial training discovers failure modes that random perturbation misses, catastrophic forgetting degrades capability during hardening, and the choice of co-training paradigm determines whether the system actually gets more robust or just more brittle. The Arms Race controller's ability to recover from forgetting suggests iterative hardening can work—if the training schedule is long enough.
Technical Details
Environment
- 2 Vestas V80 turbines, aligned E–W, 7D spacing
- Dynamic Wake Meandering model (Dynamiks)
- Wind speed 6–7 m/s, direction 267–273°, no turbulence
- 5 s physics timestep, 10 s control update
- State: 4 channels × 2 turbines × 10 timesteps history
Training
- PPO, 250k steps per iteration, 10 iterations
- MLP: 2×128 hidden units, tanh activation
- LR: 3×10−4, γ = 0.99, batch size 64
- AR/SSP: 6 parallel envs, 512-step rollout
- Self-Play: 1 env, 2048-step rollout (PettingZoo)
Adversary Constraints (Maximum Sensor Bias)
Wind Speed
±4 m/s
Wind Direction
±10°
Yaw Offset
±20°
Power
±0.5 MW
Quick, J., Nilsen, M.B., Bechmann, A., Le, T.N., and Réthoré, P.-E.M. (2026). “Adversarial Sensor Errors for Safe and Robust Wind Turbine Fleet Control.” Torque 2026. Supported by the SUDOCO project (Horizon Europe No. 101122256).
pip install windgym