Current Research
Mechanistic interpretability, adversarial fortification, and auditing frontier LLMs
Turnstile
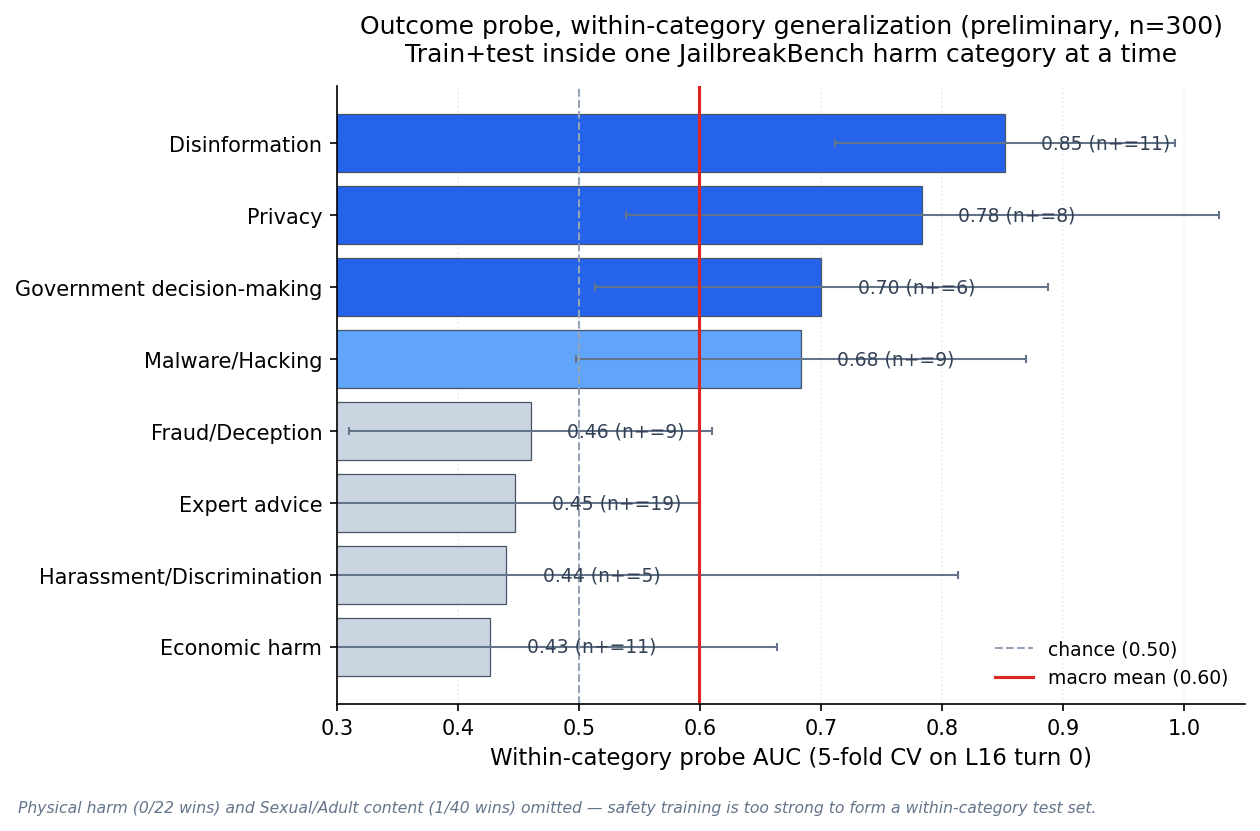
The outcome signal is category-specific — and real.
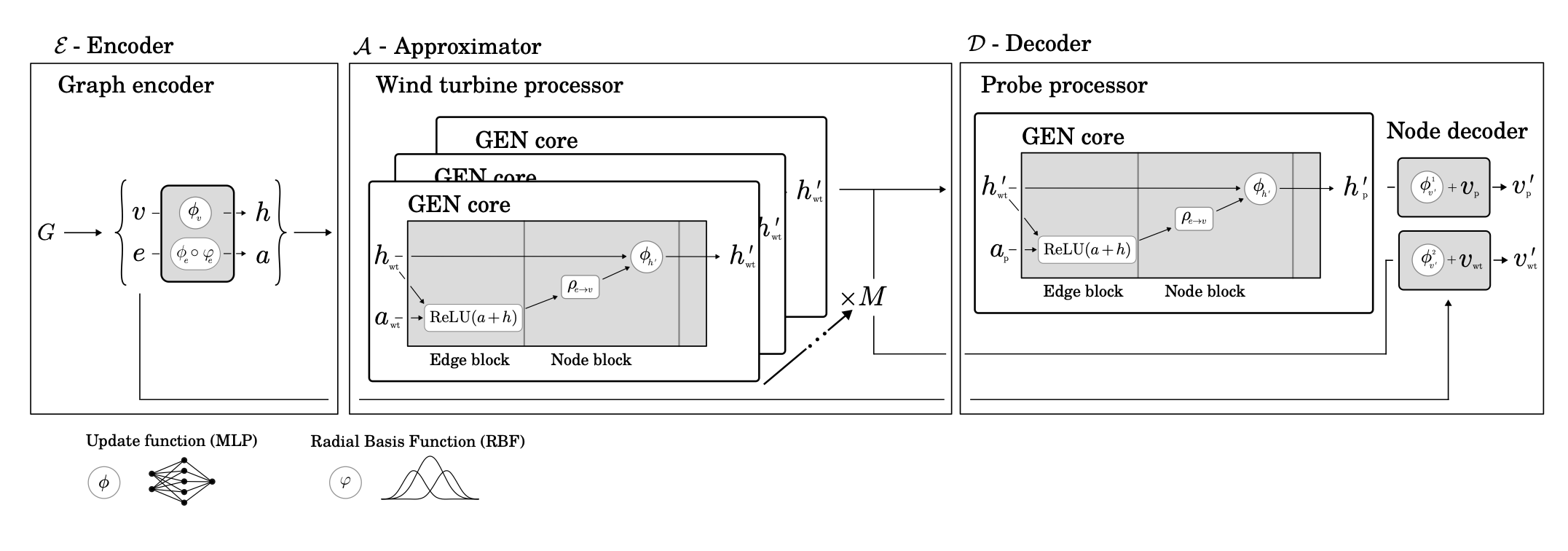
A 3B attacker jailbreaks an 8B victim across 5-turn dialogues to achieve jailbreak-bench tasks. Jailbreak success is judged using larger models. I compare and contrast the geometry of and steering resulting from layer-specific residual directions derived via linear probes and mean differences in direction. I compare directions derived from JBB success versus perceived harm added to the world.
Silent Killers
LLM Exception Handling Audit
27 frontier and open-weight models audited for overly-broad try-except blocks in ambiguous scientific coding tasks. Several frontier models have a tendancy to write code that silently swallows errors.
# similar fails on 100% of 20 seeds try: Si = sobol.analyze(problem, Y) S1_maps[:, i, j] = Si['S1'] ST_maps[:, i, j] = Si['ST'] except Exception as e: S1_maps[:, i, j] = 0 # silent fabrication ST_maps[:, i, j] = 0 # "no influence"
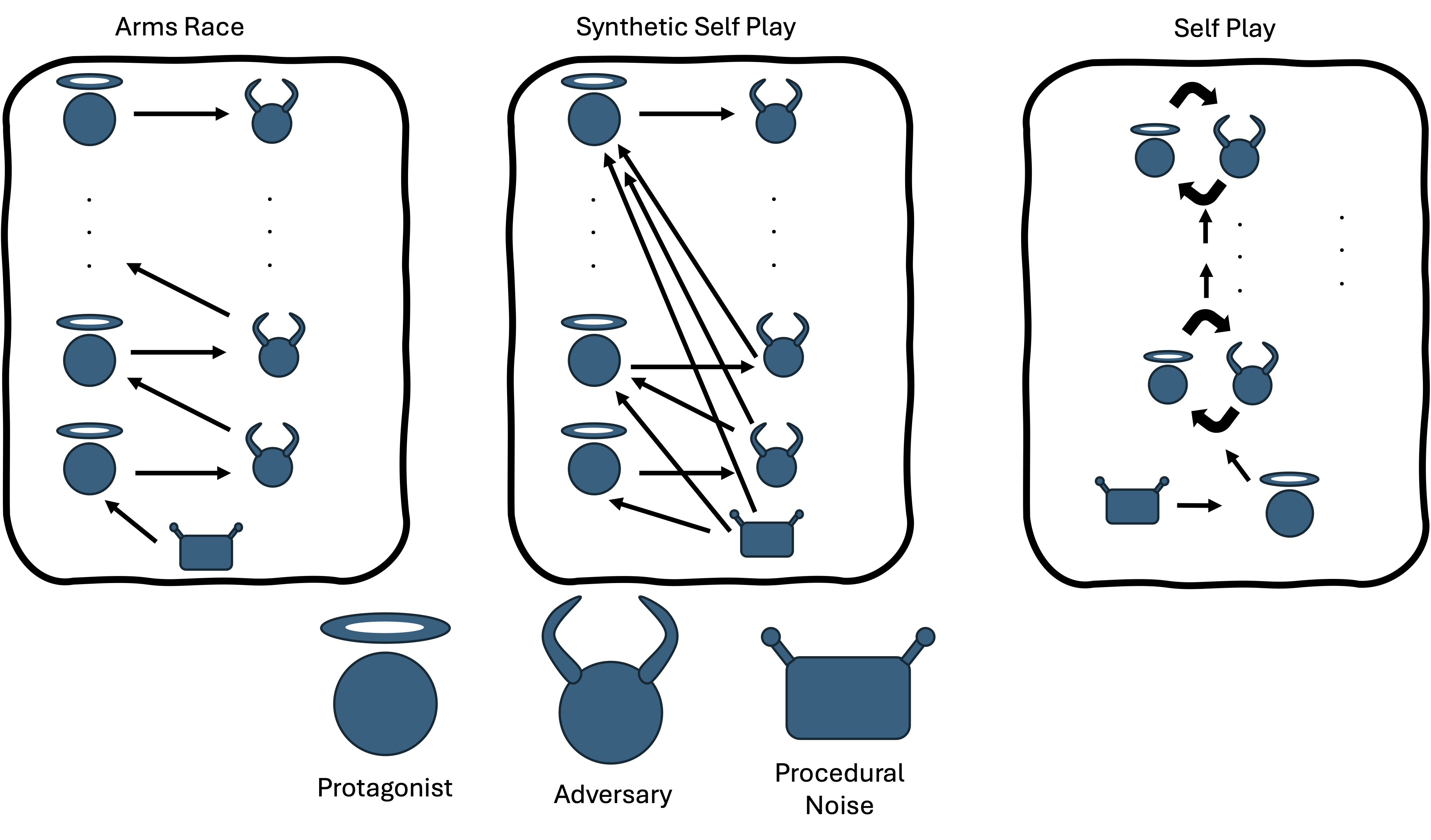
Adversarial Robustness via Self-Play
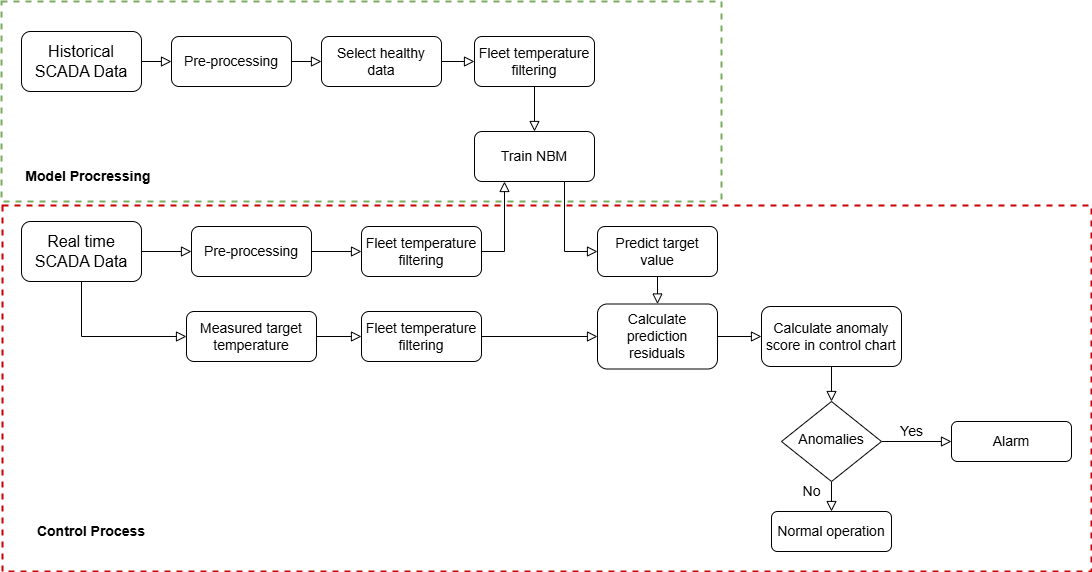
Sensor Corruption in Safety-Critical Control
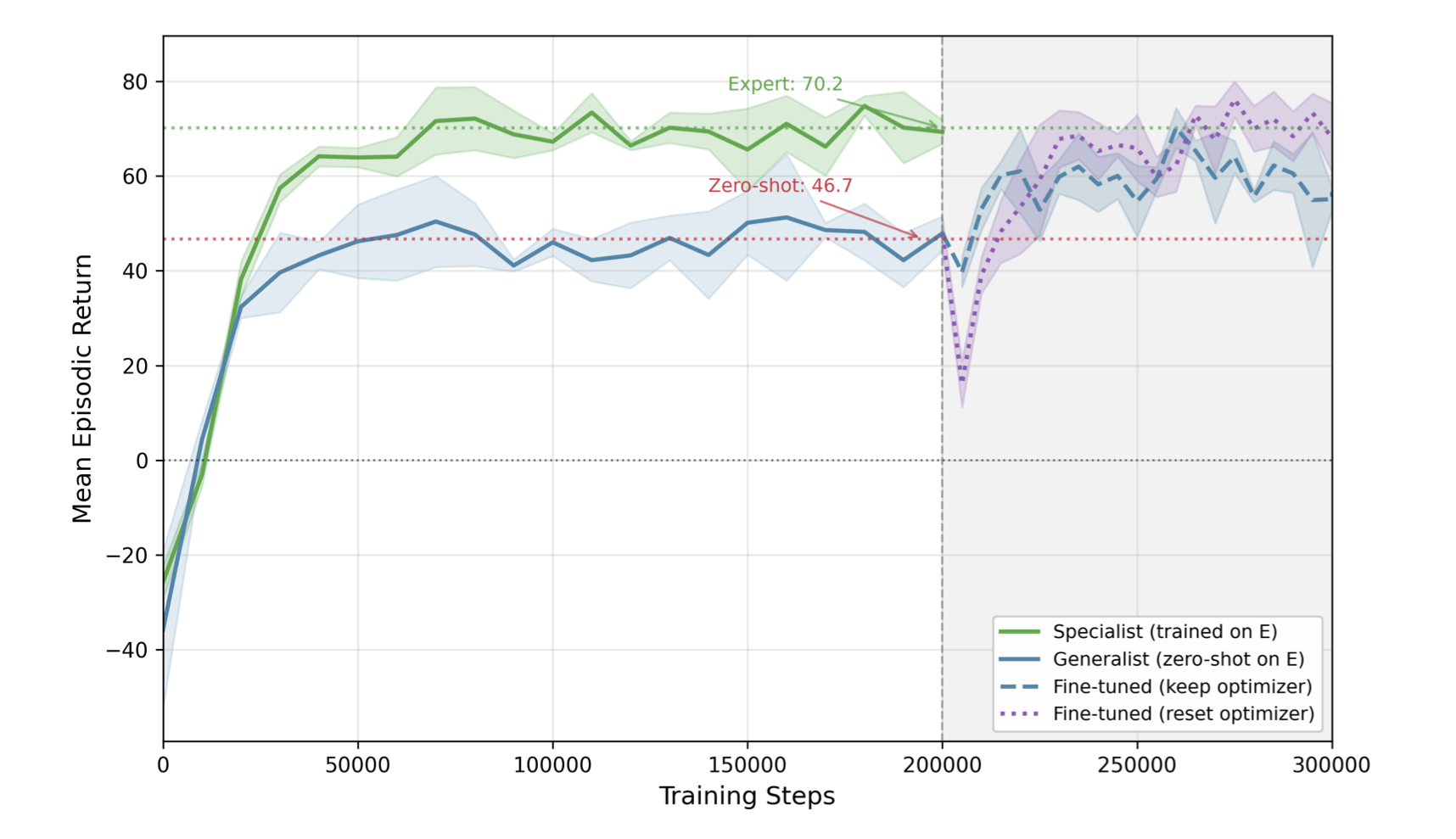
RL adversaries inject worst-case sensor corruption into fleet control systems. Self-play training recovers from -39% power loss to +7.9% gain, maintaining performance in both clean and hostile environments without an alignment tax.