Abstract
While humans generally understand that code which runs without errors is not necessarily correct, language models routinely produce exception handlers that silently swallow errors, yielding code that appears to work but producing corrupted results. We audit exception-handling in Python code generated by 25 large language models spanning seven provider families on three scientific computing tasks. An abstract syntax tree analysis across 1,500 responses (1,245 yielding parsable code) reveals that most families produce broad catches that silently suppress errors at rates up to 87% on complex tasks, through five recurring failure modes: bare catches, sentinel returns, NaN imputation, zero-fill suppression, and logged-but-suppressed errors.
Rates vary across families in ways that defy simple explanation: open-weight families with similar training diverge sharply, and reasoning-optimized models show lower rates within some provider families but not others. A temperature control experiment confirms that the variation is not a sampling artifact. A prompt ablation study reveals two regimes: on simple tasks, a single instructional sentence nearly eliminates suppression, while on complex tasks, residual rates persist, requiring static analysis as a safety net.
Key Findings
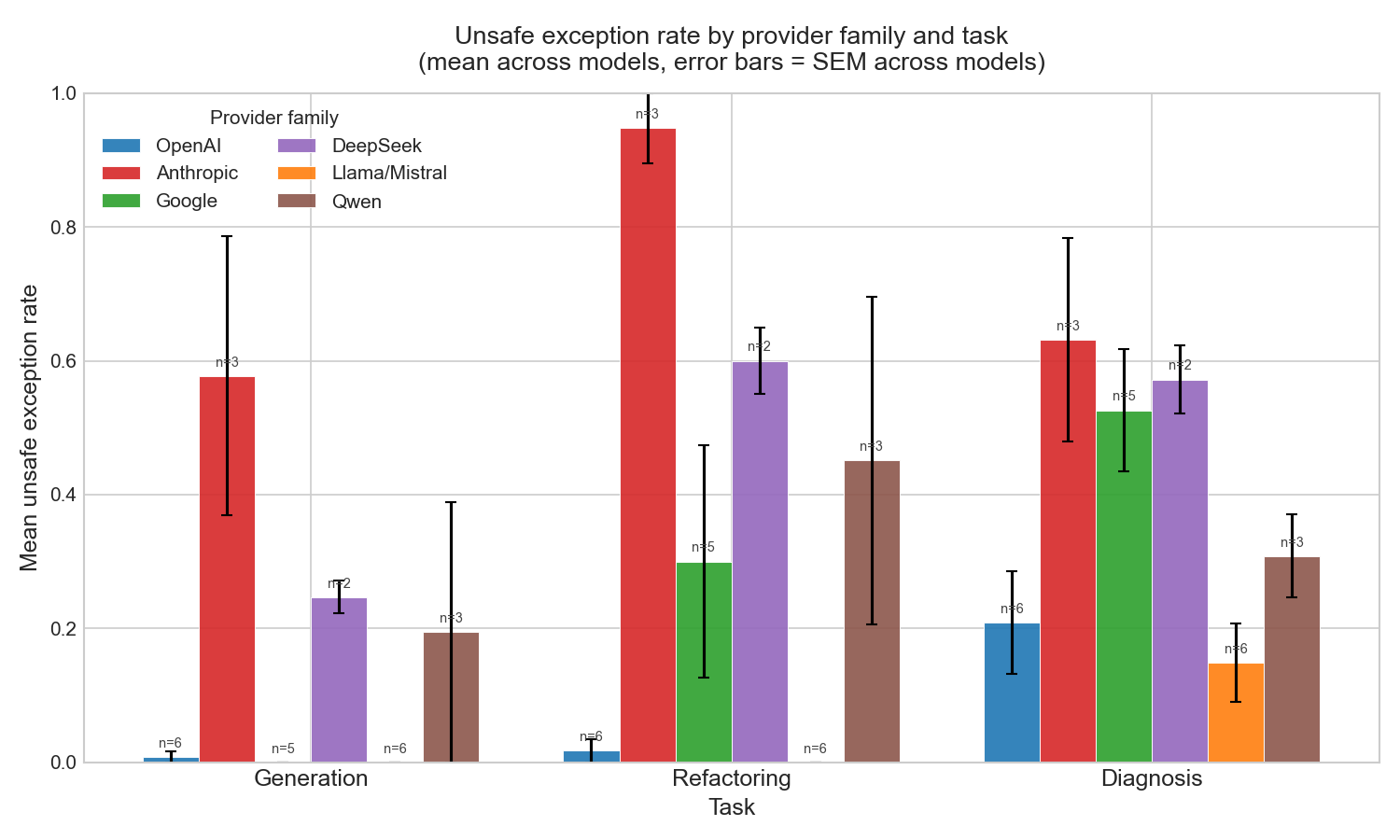
Mean unsafe exception rate by provider family and task, averaged across models within each family. Error bars show standard error of the mean across models in that family. Every family's rate rises from generation to diagnosis; Anthropic leads on the simplest task, while all families converge toward high rates on the hardest.
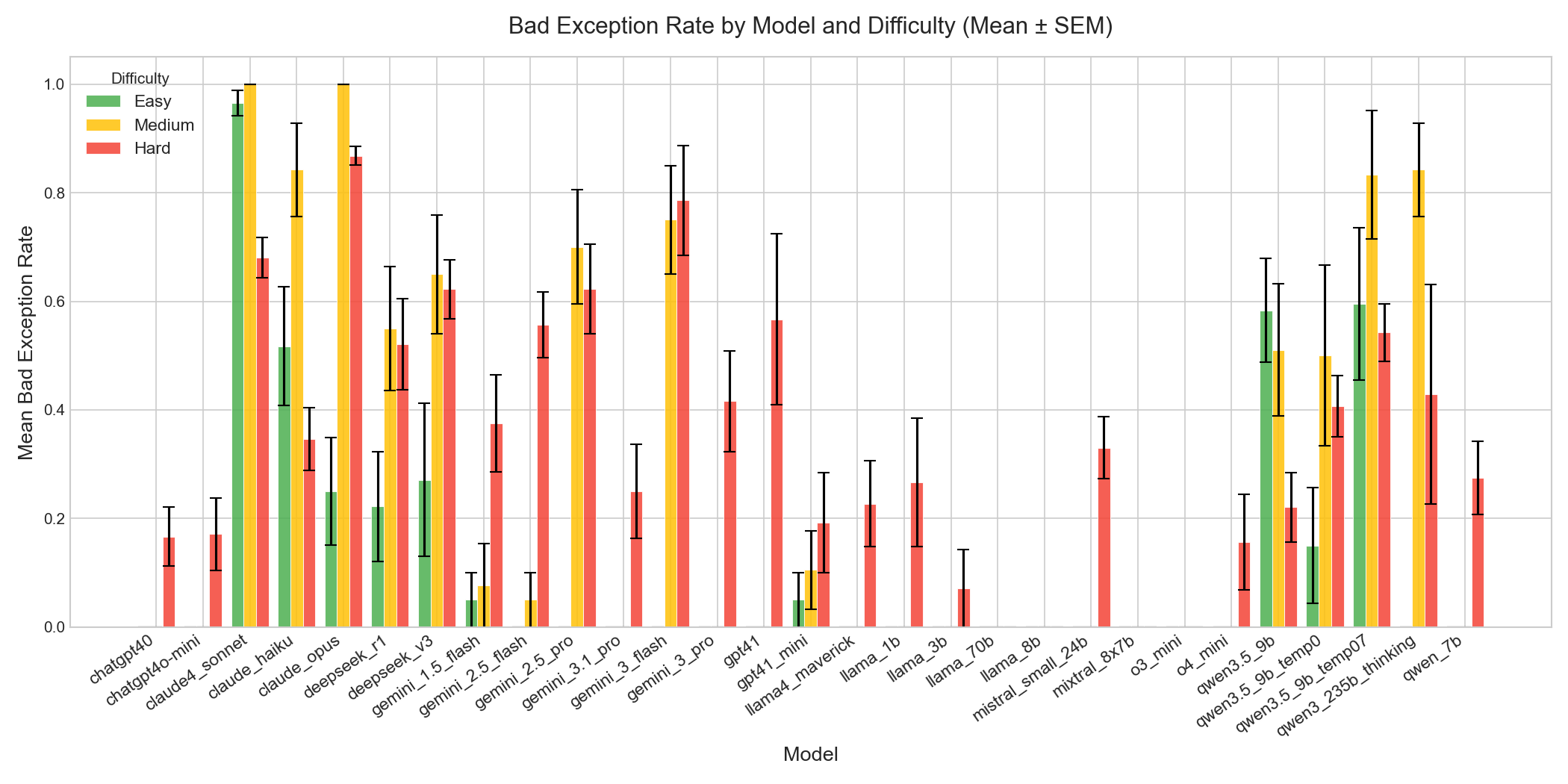
Per-model breakdown: mean unsafe exception rate grouped by task. Error bars show standard error of the mean across 20 seeds.
Reasoning models are more resilient
o3-mini never introduces a try/except block on any task. o4-mini reaches only 0.16 on diagnosis. DeepSeek R1 improves over V3 on all tasks. The consistent direction across three providers is noteworthy.
Open-weight families diverge sharply
Llama and Mistral produce 0% unsafe handlers on generation and refactoring. Qwen (also open-weight, also RLHF-tuned) shows 0.58 on generation. If RLHF monolithically caused suppression, all three should show it.
Prompt ablation reveals two regimes
On simple tasks, "always re-raise" instruction drops Claude Sonnet 4 from 0.97 to 0.04. On complex tasks, residual rates of 0.11–0.35 persist even with explicit instructions. Suppression is entangled with the model's approach to problem structure.
Per-Seed Bimodality
On simple tasks, models either introduce no handlers or only unsafe ones (all-or-nothing). On complex tasks, individual seeds mix safe and unsafe handlers. The decision to suppress errors appears to be made early and applied consistently per response, suggesting a global strategy rather than independent per-handler choices.
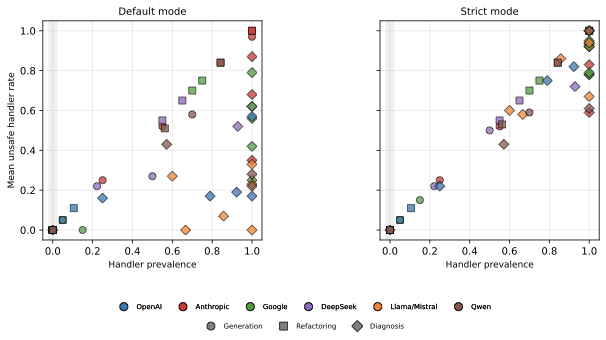
Handler prevalence vs. mean unsafe handler rate. Left: default mode (broad catches without re-raise). Right: strict mode (any handler without re-raise). Points near the y=x diagonal confirm the all-or-nothing pattern.
Case Study: Claude Sonnet 4 at 97%
Claude Sonnet 4's 97% rate on the generation task — a prompt with no mention of error handling — is the most extreme result. Across all 19 parseable seeds, Sonnet introduces blanket catches; in 17 of 19 seeds every handler is unsafe. One handler replaces simulation output with a constant array on exception; another zero-fills Sobol indices:
try:
Si = sobol_analyze.analyze(self.problem, Y)
S1_maps[:, i, j] = Si['S1']
ST_maps[:, i, j] = Si['ST']
except Exception as e:
S1_maps[:, i, j] = 0
ST_maps[:, i, j] = 0
Sensitivity indices of 0.0 mean "this parameter has no influence" — the exact opposite of what a failed analysis should communicate. This pattern is deterministic across all 19 parseable seeds. Prompt ablation drops this to 0.04, but on the complex diagnosis task, residual rates of 0.35 persist.
Five Failure Modes
Across 790 unsafe handlers, we identify five recurring patterns through which models suppress errors. Each produces code that executes without user-visible errors while silently corrupting results.
Bare catch + pass/continue
except: continue skips iterations. Biases aggregates toward successful cases.
Sentinel value returns
Returns -0.5, -1, or 999 on failure. Optimizer treats sentinel as excellent fit. Most prevalent (38%).
NaN imputation
Replaces output with np.nan. np.nanmean silently ignores failures downstream.
Zero-fill suppression
Sets Sobol indices to 0. Reports "no influence" when analysis actually failed.
Logged-but-suppressed
Logs warning, falls back to default. Returns uncalibrated parameters as calibrated. Hardest to detect in review. Second most prevalent (37%).
Prompt Ablation: Two Regimes
Adding a single instruction — "Do not use broad try/except blocks that silently suppress errors. If you catch exceptions, always re-raise them." — reveals that suppression has two distinct regimes:
| Model |
Generation |
Diagnosis |
|
Original |
+Re-raise |
Original |
+Re-raise |
| Claude Sonnet 4 | 0.97 | 0.04 | 0.68 | 0.35 |
| DeepSeek V3 | 0.27 | 0.00 | 0.62 | 0.24 |
| GPT-4.1 | 0.00 | 0.00 | 0.57 | 0.11 |
| o3-mini | 0.00 | 0.00 | 0.00 | 0.00 |
| Qwen3.5-9B | 0.58 | 0.14 | 0.22 | 0.26 |
Simple tasks: suppression is a shallow default, trivially overridden (0.97 → 0.04).
Complex tasks: residual rates of 0.11–0.35 persist even with explicit instructions, indicating suppression is entangled with the model's approach to problem structure. Static analysis is required as a safety net.
Difficulty Breakdown
Three scientific computing tasks of increasing complexity, all grounded in wind energy simulation using PyWake: generation (~30 LOC), refactoring (~100 LOC), and diagnosis (~300+ LOC). Harder tasks elicit more handlers and worse rates.
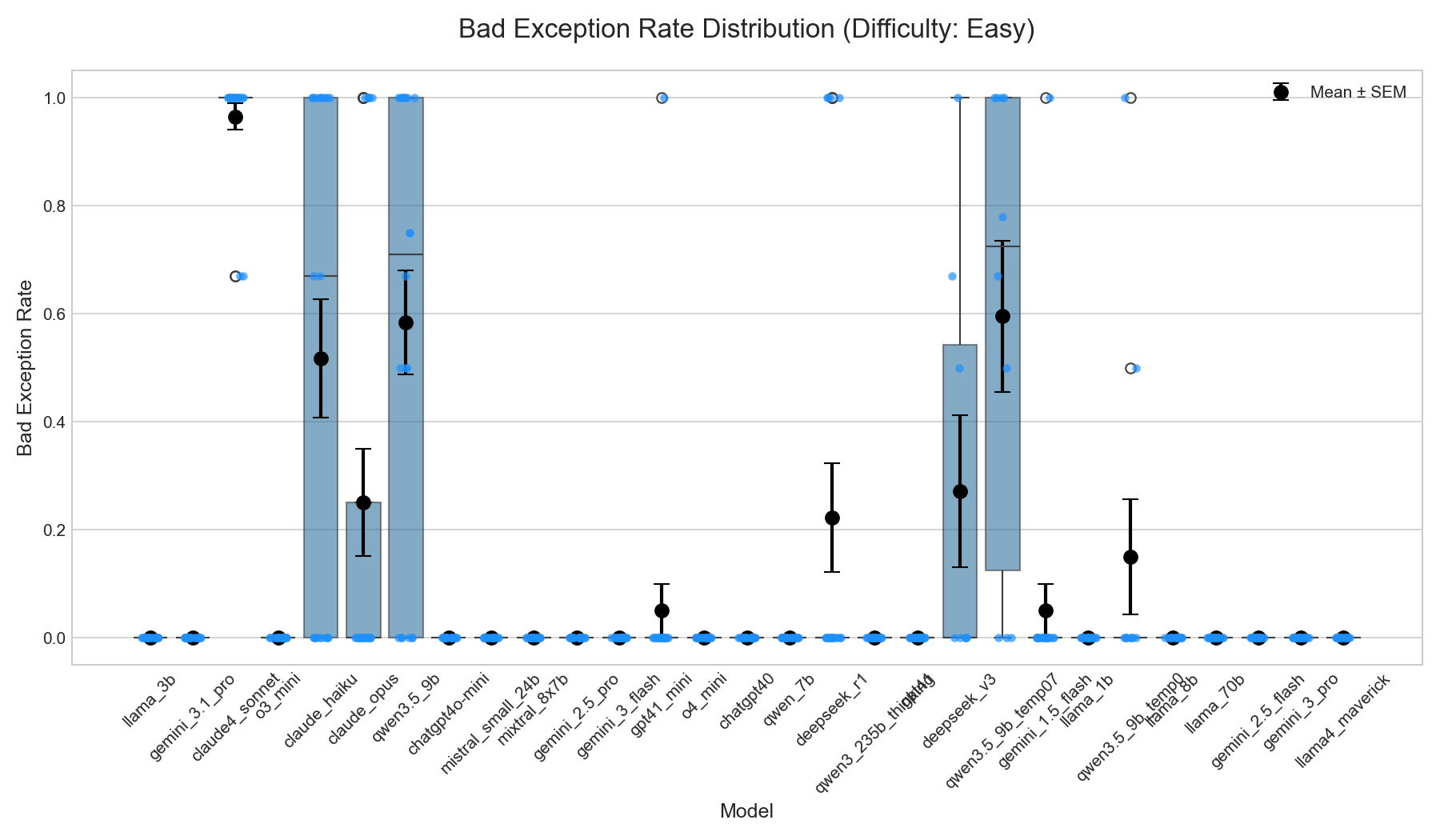
Generation (~30 LOC)
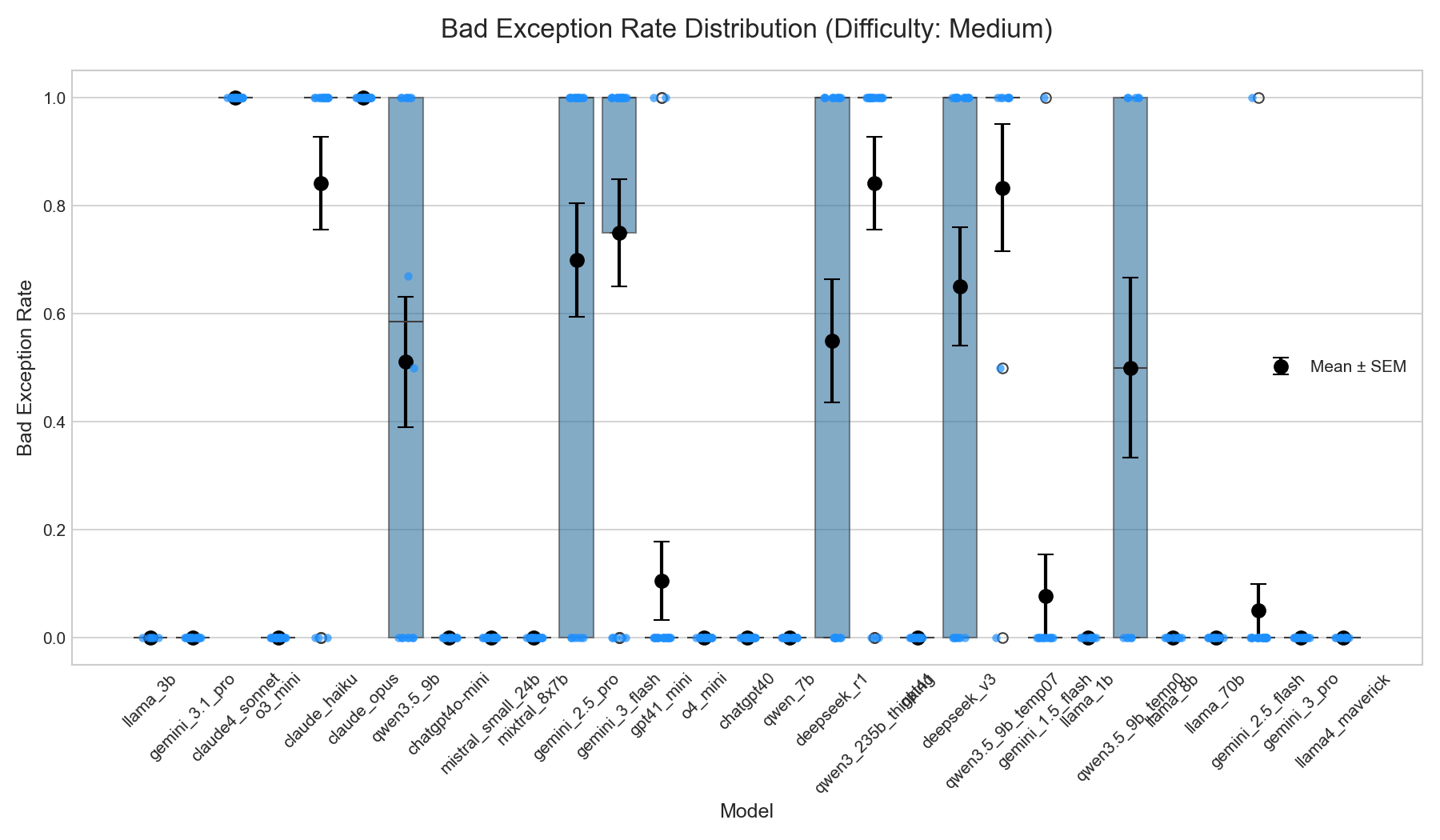
Refactoring (~100 LOC)
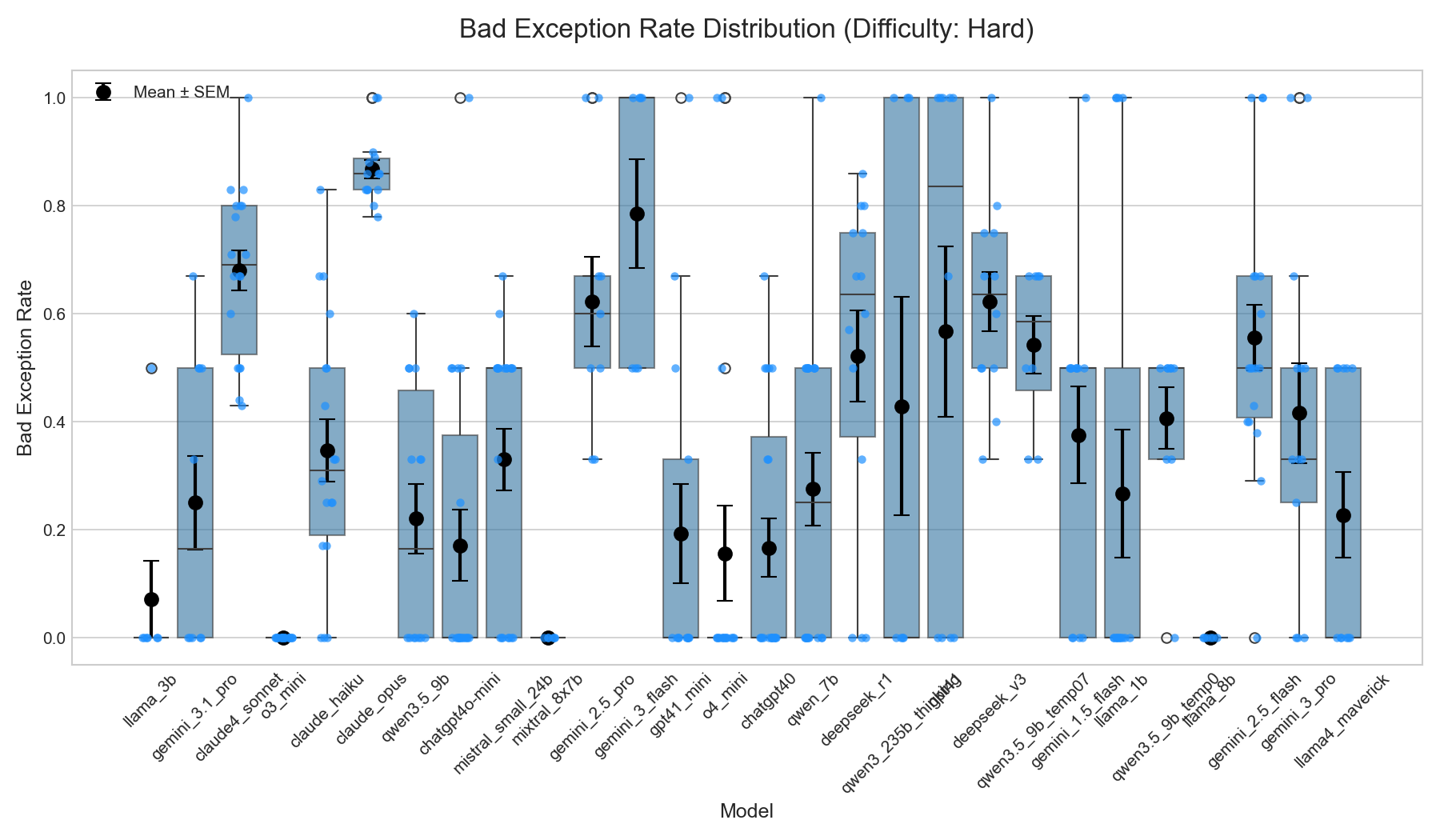
Diagnosis (~300+ LOC)
Robustness Checks
Temperature control
Qwen3.5-9B at T=0 vs T=0.7: lowering temperature reduces the rate from 0.58 to 0.15 on generation (fewer seeds introduce handlers), but on diagnosis T=0 yields 0.41 — both far above o3-mini's 0.00. Temperature does not account for the reasoning-model contrast.
Cross-domain generalization
A BioPython bioinformatics task (pairwise protein alignment, phylogenetic tree construction) on 4 models confirms the pattern extends beyond wind energy: Claude Sonnet 4 shows 77% unsafe rate with 100% handler prevalence. Error suppression is not specific to PyWake.
Per-Model Results
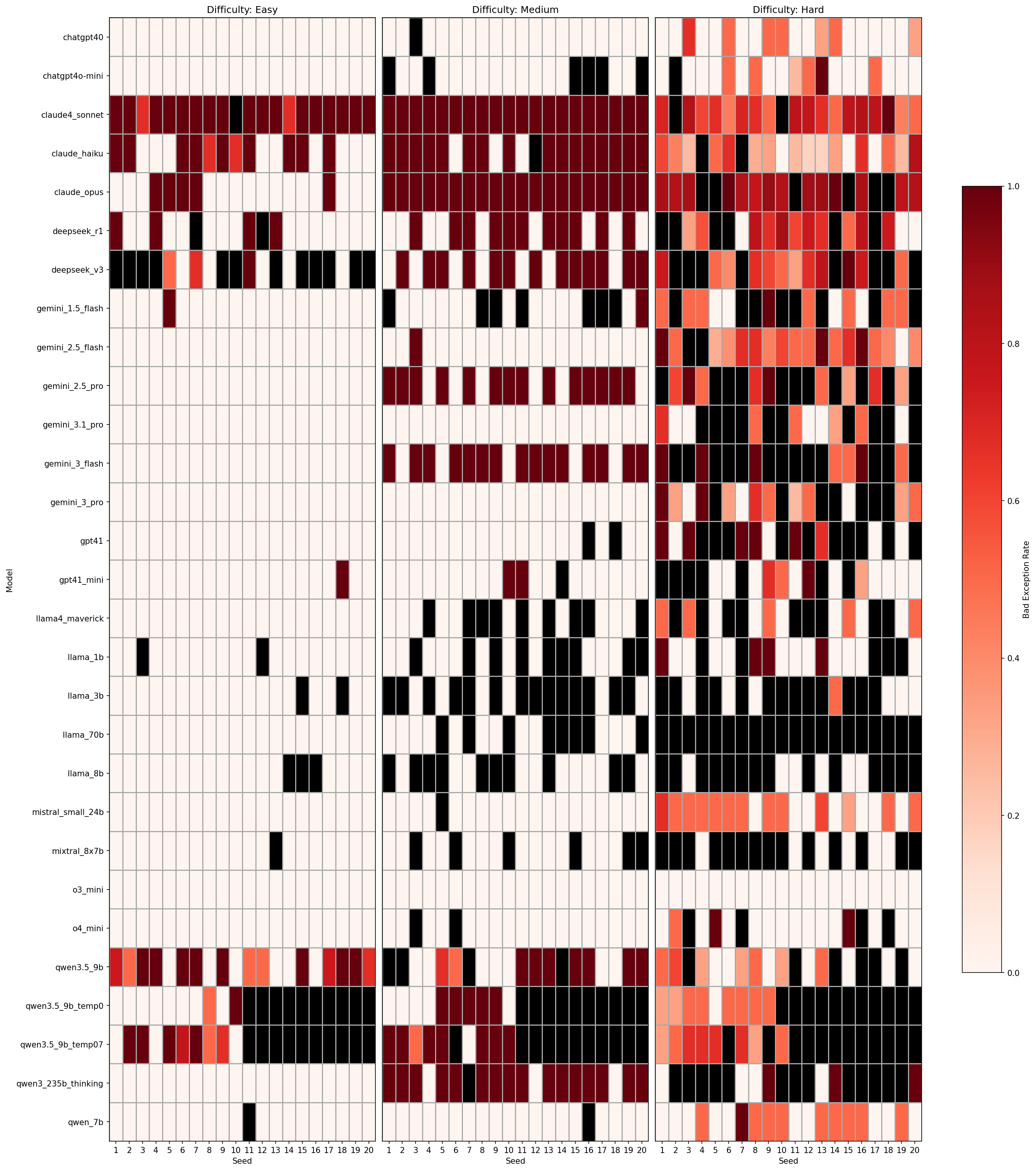
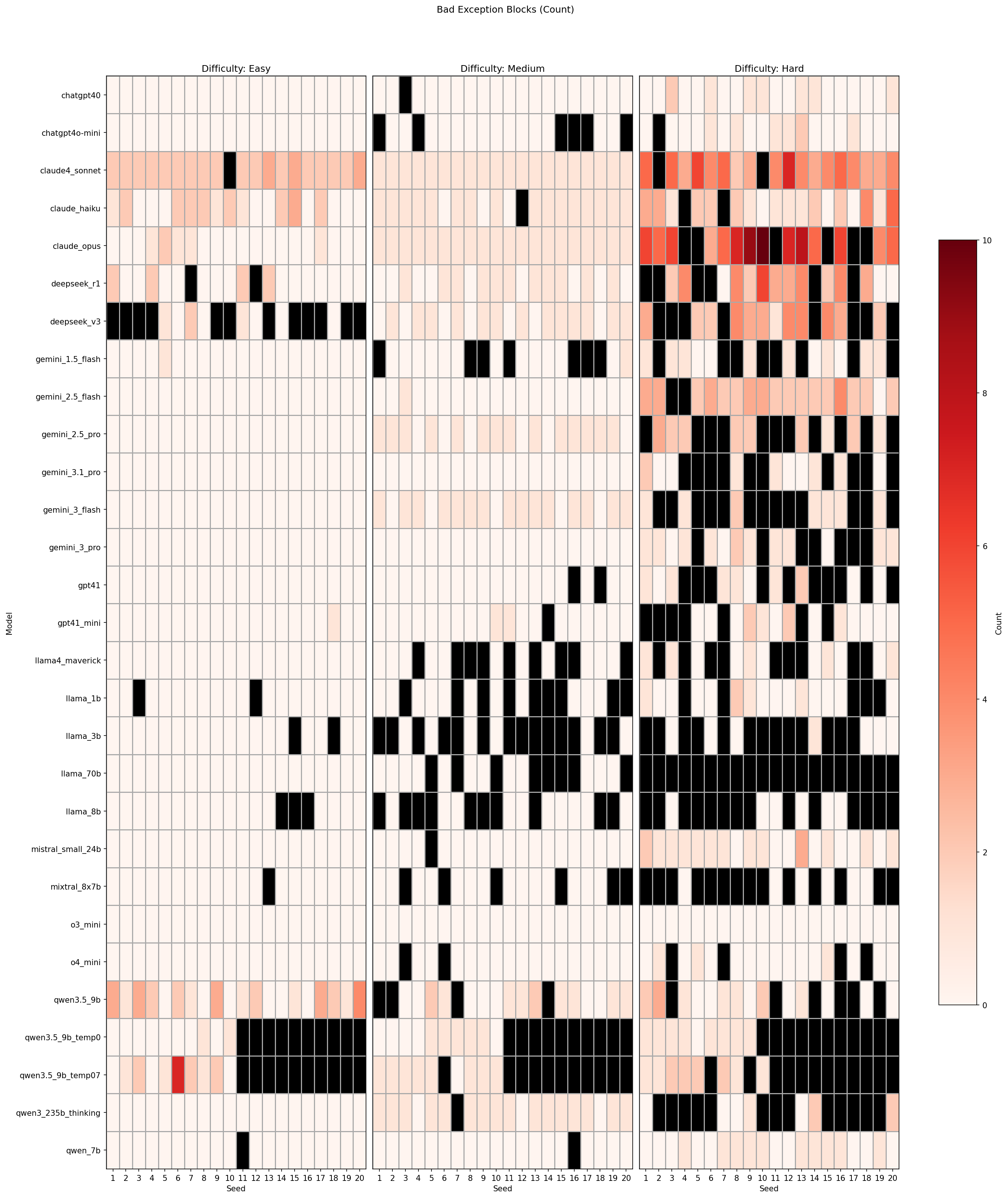
Per-seed unsafe exception rate (fraction of handlers that don't re-raise). Darker red = higher unsafe rate.
Data Quality
Of 1,500 LLM responses, 1,245 yield at least one valid Python block. Attrition comes from prose-only responses, code outside markdown fences, and syntax errors. Attrition is highest for the smallest open-weight models (Llama 3.2 1B/3B).
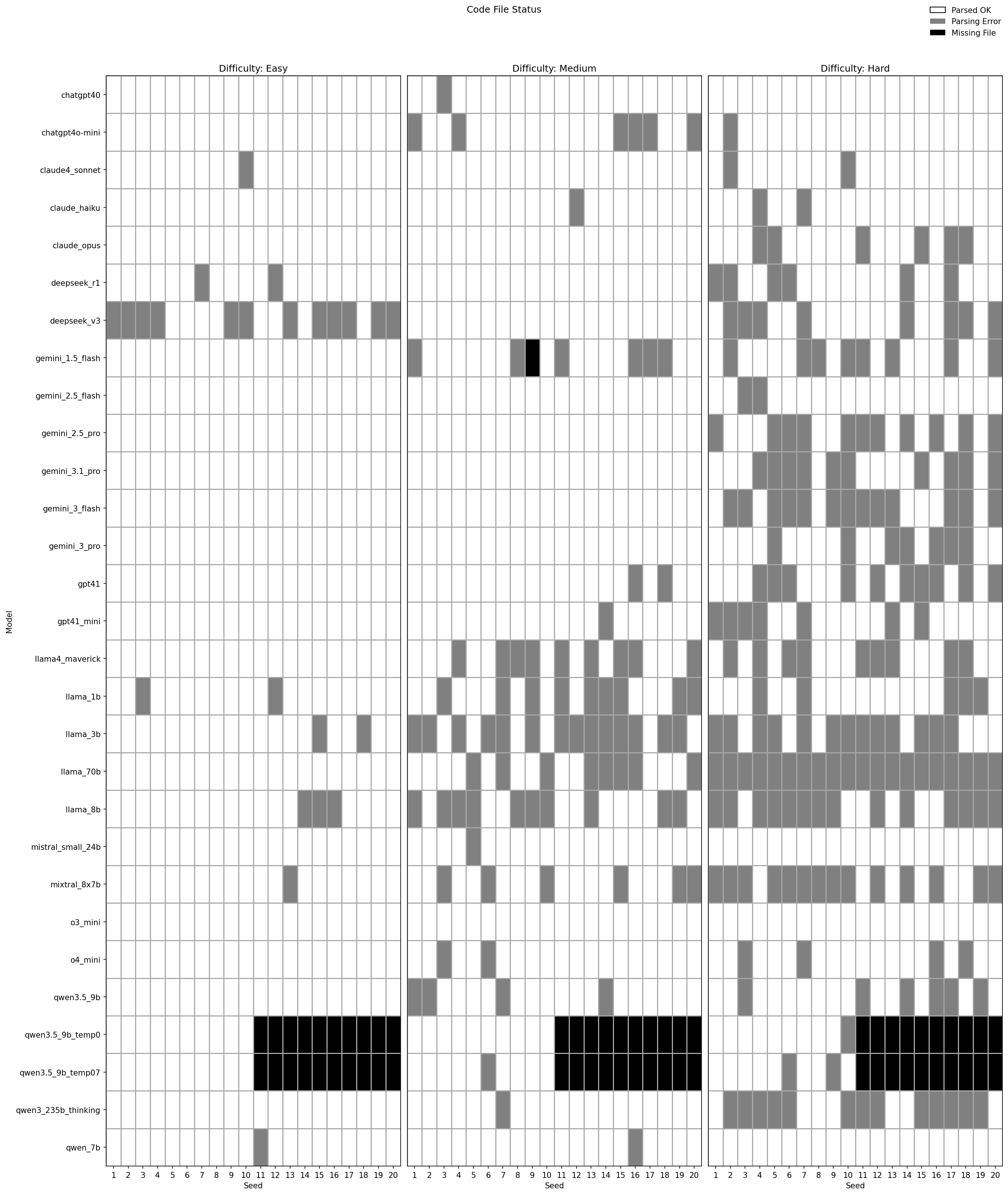
Seed-level parse status across all models and difficulties
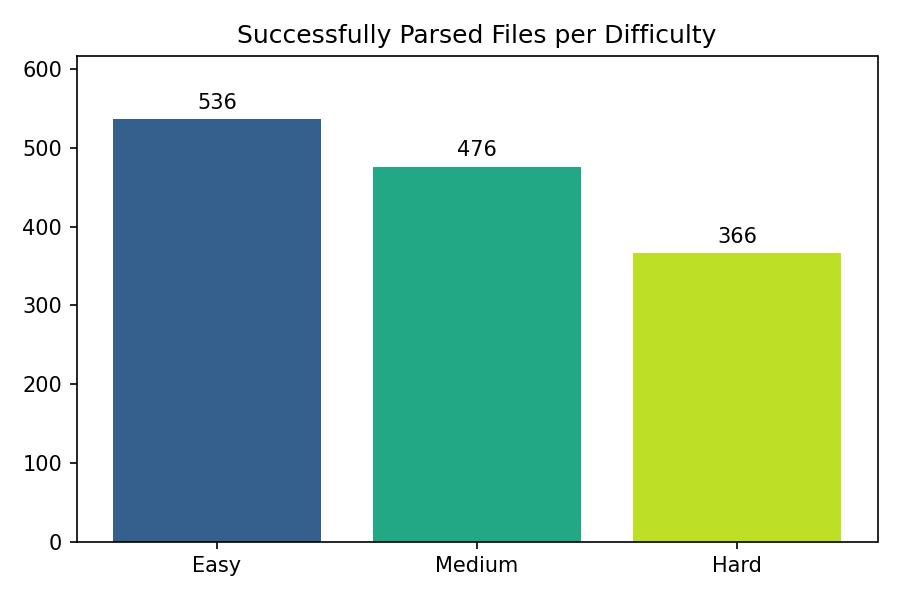
Successfully parsed responses by difficulty level
Methodology
A handler is classified as unsafe if and only if it satisfies both conditions: (1) Broad catch — the except clause catches Exception, BaseException, or uses a bare except:, and (2) No re-raise — the handler body contains no raise statement. This two-criterion test is conservative: handlers that catch broadly but re-raise are classified as safe, and handlers targeting narrow exceptions (e.g., FileNotFoundError) are excluded.
The open-source silent-killers PyPI package provides both this default mode and a strict mode (any handler without raise, regardless of exception type) for safety-critical contexts.
Why It Matters
- Proxy satisfaction: Models may optimize for "code runs without visible errors" rather than "code is correct" — a concrete instance of Goodhart's Law in code generation.
- Evaluation brittleness: Pass@k and execution-accuracy benchmarks do not penalize silent suppression. A script that swallows all exceptions will pass every execution test.
- Agentic amplification: In multi-step pipelines (ReAct, SWE-agent), a suppressed exception produces output that looks valid to downstream steps, compounding errors invisibly.
- Reproducibility under $100: All experiments use publicly available model APIs and open-weight models. The full study can be reproduced for under $100 in API costs.