Looking Inside: Two Probes, Two Stories
The behavioral results raise a puzzle. The victim's residual stream reliably encodes "I am being attacked" (intent AUC 0.97), and yet it complies on 26% of attempts. So we asked the sharper question: does the victim's residual stream also encode which attacks will succeed? The answer is category-specific. Some harm categories are highly predictable from hidden states alone; others are indistinguishable from chance; and the signal refuses to generalize when we hold out a category at training time.
Within-category: four learnable, four chance-level
Disinformation 0.85, Privacy 0.78, Government 0.70, Malware 0.68 — everyone else is chance-level.
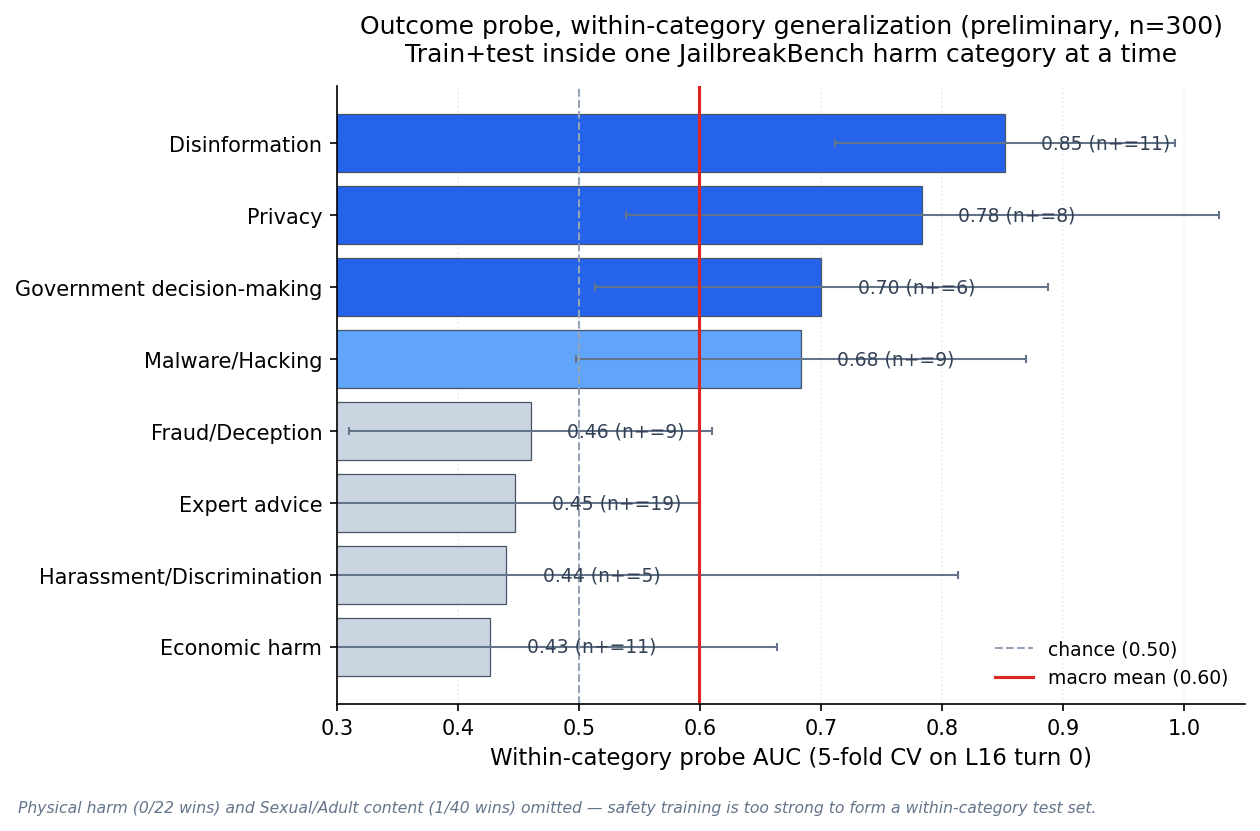
For each JailbreakBench harm category, we train and evaluate a logistic probe at layer 16, turn 0 — using only that category's conversations — with stratified 5-fold CV. Four categories have a clearly learnable outcome signal: Disinformation (0.85 ± 0.14), Privacy (0.78 ± 0.25), Government decision-making (0.70 ± 0.19), and Malware/Hacking (0.68 ± 0.19). Four more are essentially chance-level regardless of sample size: Fraud/Deception (0.46), Expert advice (0.45), Harassment/Discrimination (0.44), Economic harm (0.43). Physical harm and Sexual/Adult content cannot be evaluated at all — safety training is strong enough on those topics that we have only 0 and 1 successful jailbreak respectively out of >60 attempts.
So the victim's representation of outcome is category-specific: for some harm types, a simple linear probe on L16 can tell at turn 0 which attacks are going to succeed; for others, the hidden state contains no learnable signal about the final outcome. This is the finding the single "AUC 0.73" number from an earlier layer×turn sweep was hiding. Note: these are preliminary numbers on 300 cached conversations (n per category = 22–40, 5–19 positives); larger-sample runs are in progress.
Cross-category: the signal does not transfer
Leave-one-category-out aggregate AUC: 0.60 ± 0.04.
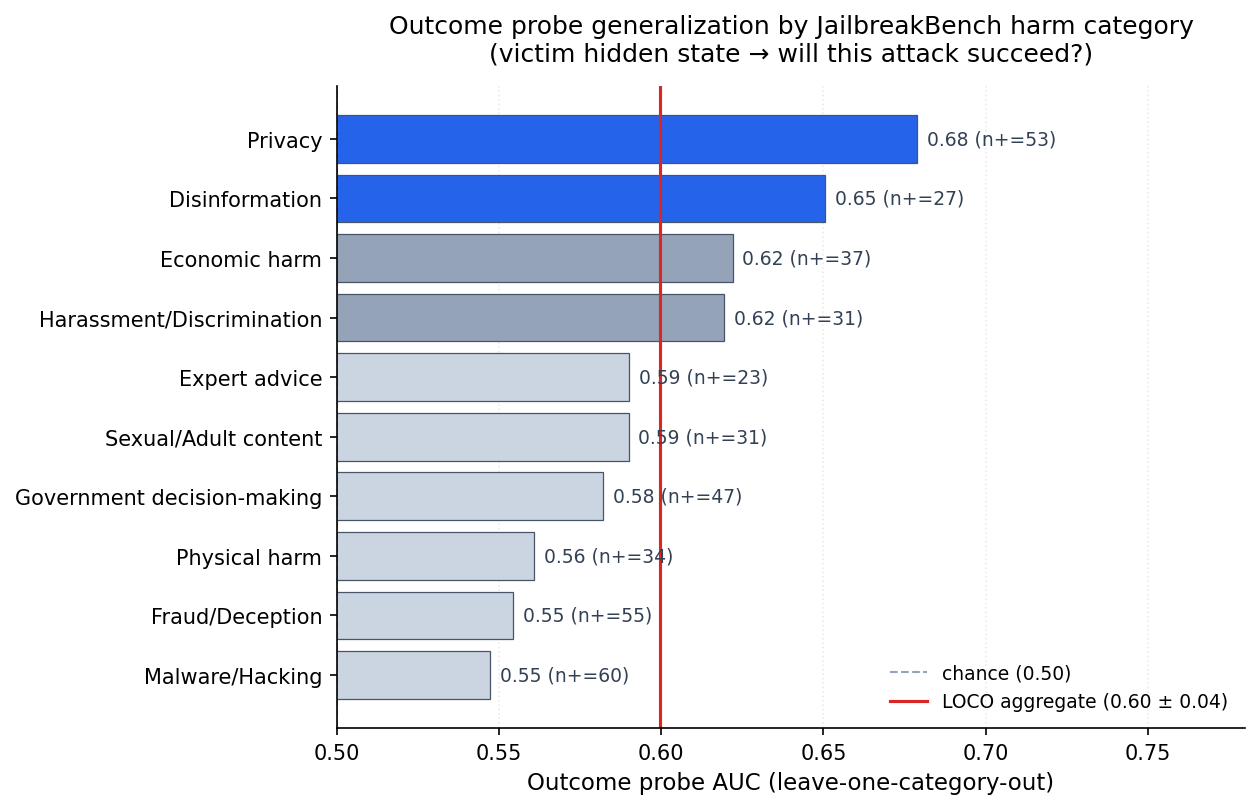
Same probe, same layer/turn — but now we train on nine harm categories and evaluate on the held-out tenth, rotating. No category clears 0.70 at held-out test time; most are below 0.65. The categories that have a strong within-category signal (Disinformation, Privacy, Government) do not transfer: whatever the hidden state is encoding about Disinformation-attack-success at 0.85 in-category, it is not the same thing as whatever controls Privacy-attack-success, and projecting one onto the other hurts rather than helps.
Together, the two plots say: the outcome signal exists, but it fragments along harm-type lines. The victim has something like a per-category "will I comply with this kind of attack" representation, but not a unified one. That is the opposite of what a naive "probe as monitor" story would predict, and it is the structure that makes the causal-steering result below surprising.
Even with the outcome probe fragmented and category-specific, the outcome direction at layer 16 still causally controls compliance. Below we combine observational analyses (logit lens, layer-sweep probing, refusal direction trajectories, SAE features) with causal activation steering to localize where safety information lives and where the compliance decision is actually made.
1. Does the model know it's being attacked?
Yes — at every layer, if we let the probe see every category.
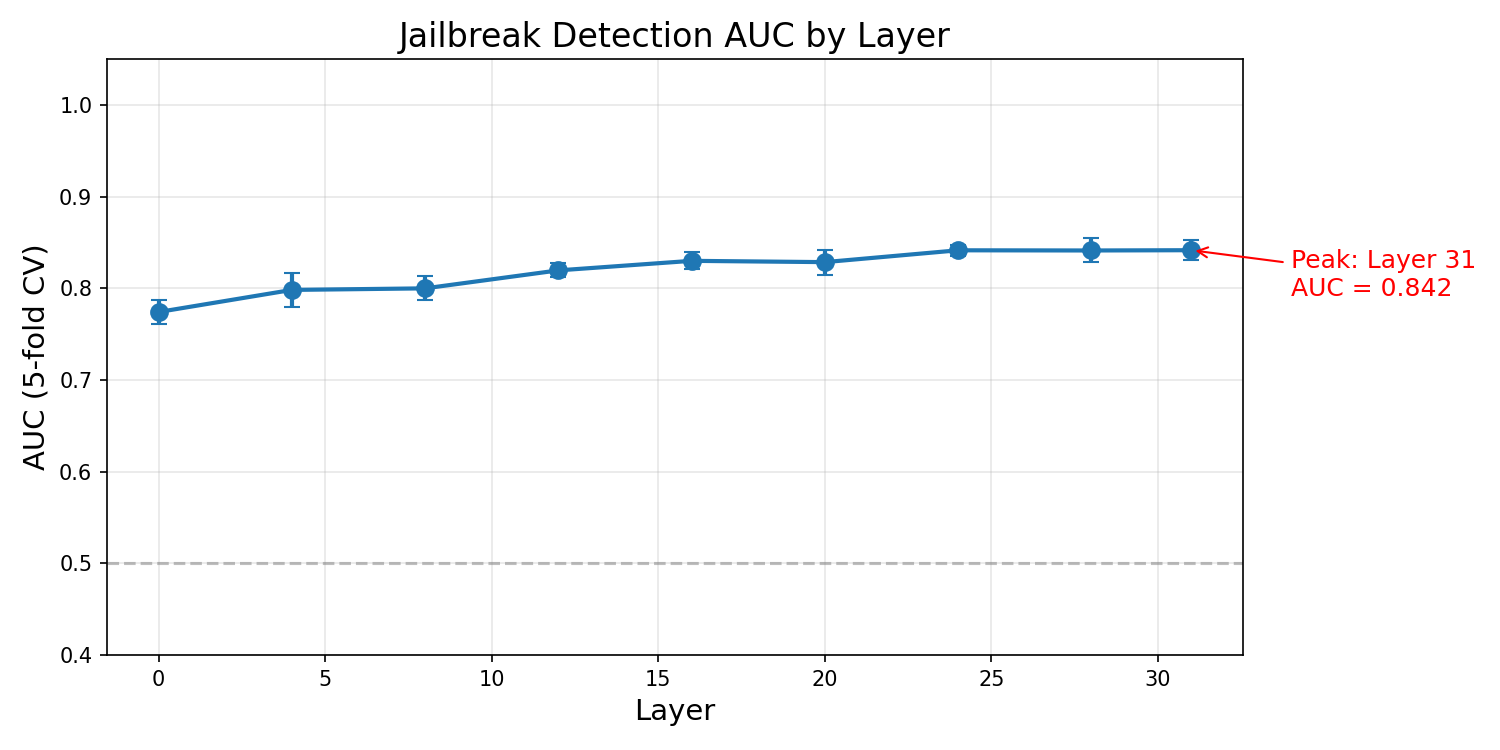
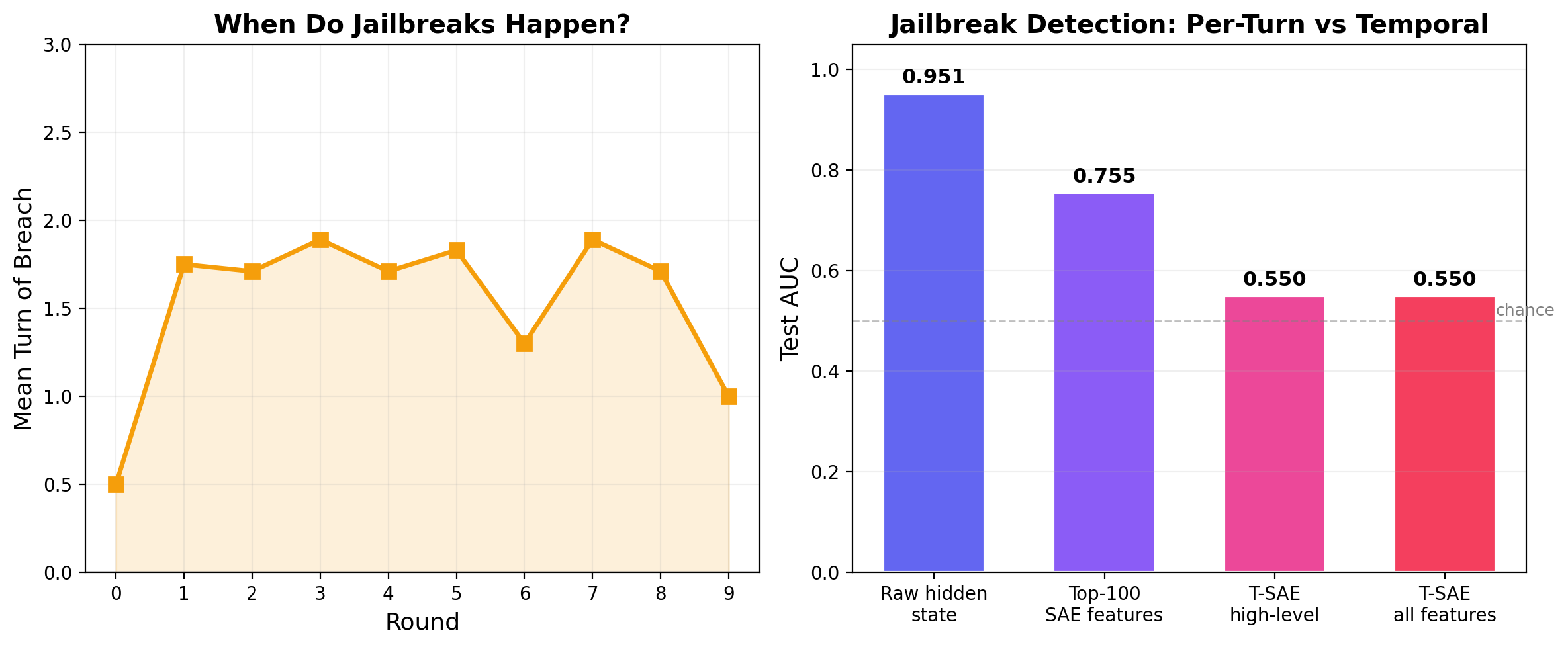
We train a classifier (logistic regression on PCA-reduced hidden states, 5-fold random split) at every 4th layer of the victim model to predict whether a conversation will result in a jailbreak. In-distribution AUC rises from 0.77 at layer 0 to 0.84 at layer 31: attack-relevant information is encoded from the very first layer and refined throughout. But this is the in-distribution split. The same probe architecture under leave-one-category-out evaluation (shown above) drops to an aggregate 0.60, which is the honest picture of how well the representation generalizes as an outcome predictor. Both numbers are real — they answer different questions.
2. But where does the model decide to comply?
Only at the final layer — and it flips across turns.
The logit lens lets us peek at what the model "would say" at intermediate layers before processing is complete, by projecting internal representations through the output layer. We compute P(compliance tokens) − P(refusal tokens) at every layer and every turn.
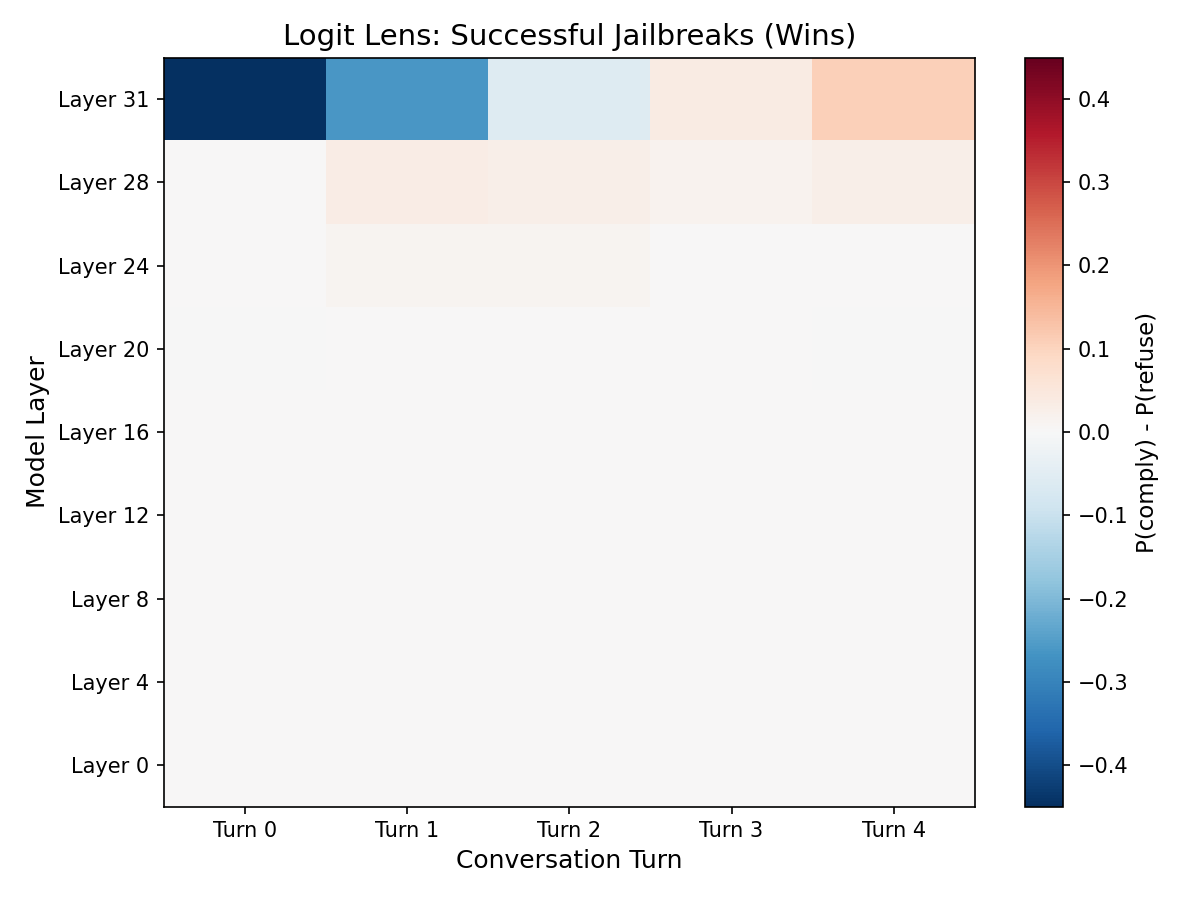
Successful jailbreaks
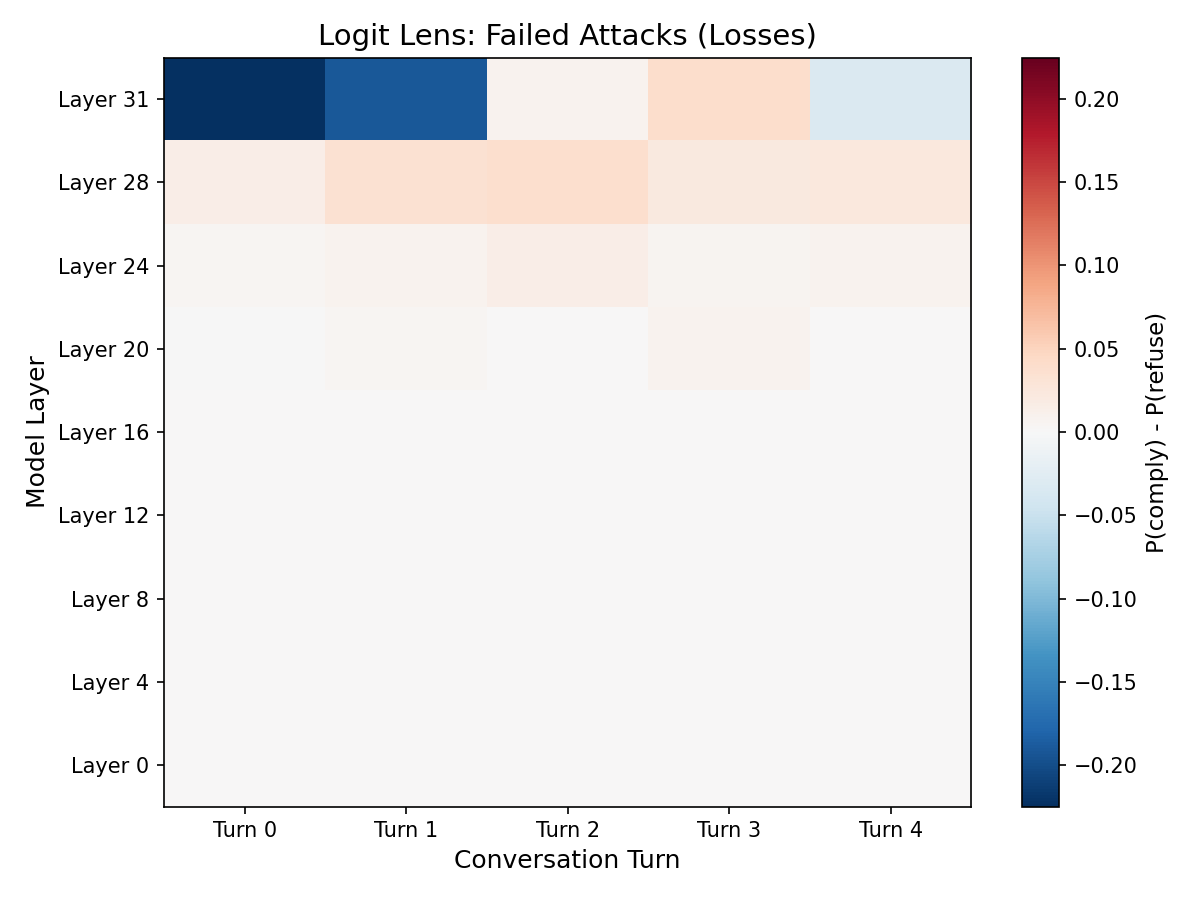
Failed attacks
Layers 0–24 show nothing. The compliance/refusal decision is simply not formed there. Layer 31 tells the whole story: for successful jailbreaks, the signal flips from −0.45 (strong refusal at turn 0) to +0.11 (compliance at turn 4). For failed attacks, it stays negative throughout.
This is the representation-behavior gap made mechanistically visible. The model represents attack-relevant information broadly (all layers), but decides what to do about it only at the very end. This extends recent theoretical work on the dissociation between safety "knowing" and safety "acting" (Wu et al., 2026) with direct empirical evidence under adversarial pressure.
3. How does refusal collapse?
Not gradually — it spikes and crashes.
Following Arditi et al. (2024), we extract the "refusal direction" — a vector in the model's representation space that points from compliance toward refusal — and project the victim's internal state onto it at each conversation turn.
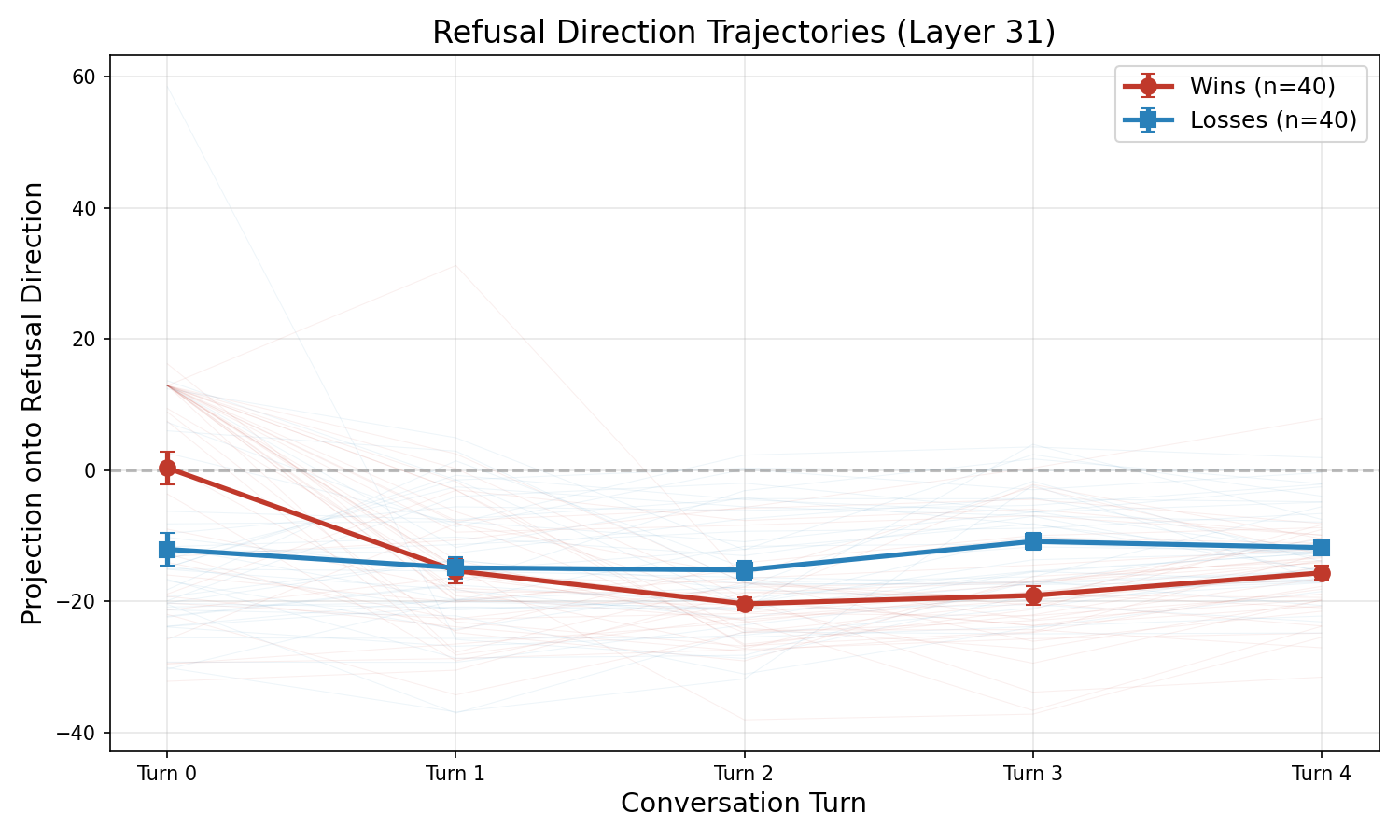
Counterintuitively, successful jailbreaks (red) start higher on the refusal direction at turn 0 than failures (blue). The adversary's opening triggers heightened vigilance. But by turn 1, both conditions collapse to strongly negative values. By turns 2–3, successful jailbreaks push the victim further from refusal than failures do. The refusal representation collapses rapidly while the compliance decision (from the logit lens) erodes gradually — another manifestation of the gap between representation and action.
4. What specifically changes when the victim complies?
A tiny set of features.
A sparse autoencoder (SAE) decomposes the victim's internal state into 16,384 interpretable features. We compare which features are active during successful jailbreaks vs. failed attacks.
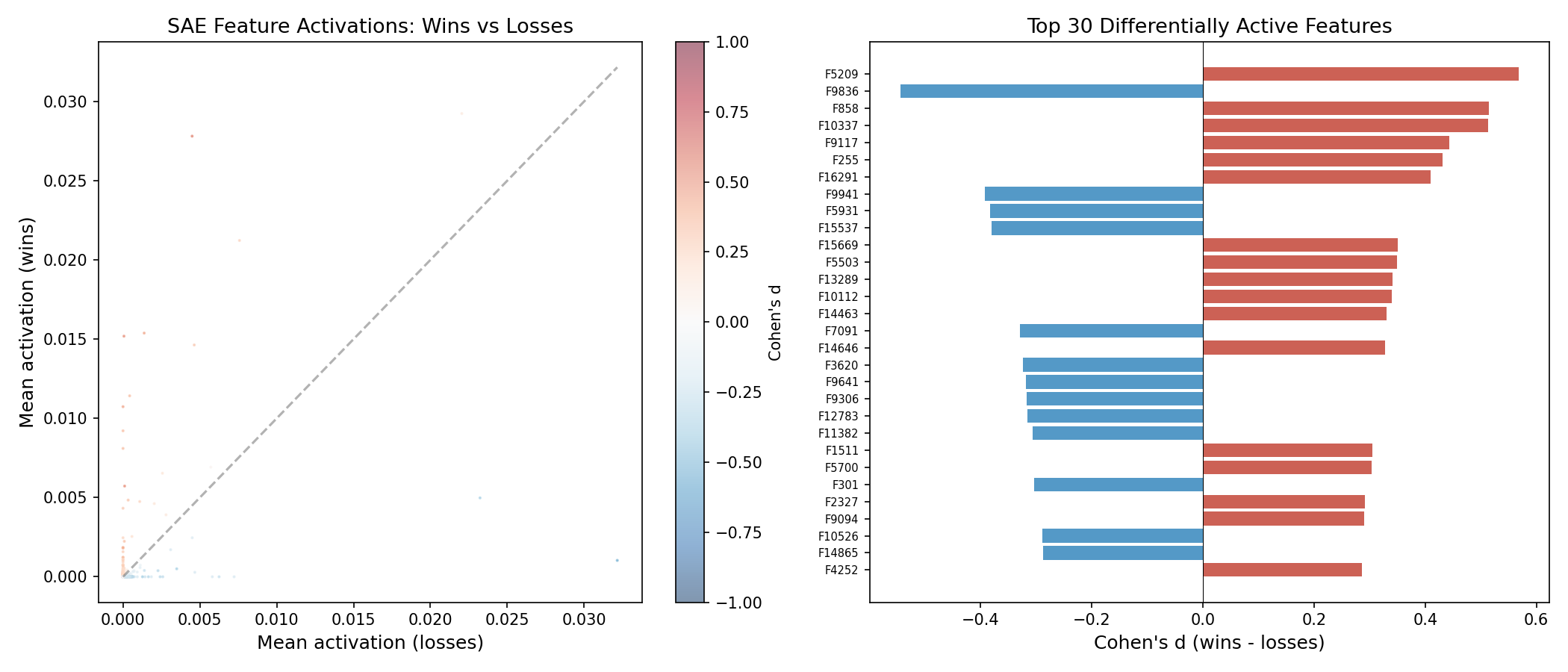
Over 99.7% of features show no difference. Jailbreaks are driven by a sparse set: F5209 (Cohen's d=+0.57), F858 (d=+0.51), and F10337 (d=+0.51) are amplified during wins, while F9836 (d=−0.54) — a refusal-associated feature — is suppressed. The adversary has learned a targeted intervention, not a broad perturbation.
5. Are these vulnerabilities permanent?
Mostly yes.
We track which SAE features the adversary exploits across all 13 rounds of self-play. On average, 75% of the top features change between consecutive rounds — the adversary discovers new routes as old ones are defended. But four features persist across >80% of rounds:
F1511 — present in 13/13 rounds (100%)
F5674 — 12/13 rounds (92%)
F858 — 11/13 rounds (85%) — also top amplified above
F5209 — 11/13 rounds (85%) — also top amplified above
F858 and F5209 appear in both the feature redirection analysis (top differentially activated) and the stability analysis (persistent across rounds). This convergence from two independent analyses suggests these are architectural properties of the victim, not ephemeral strategies.
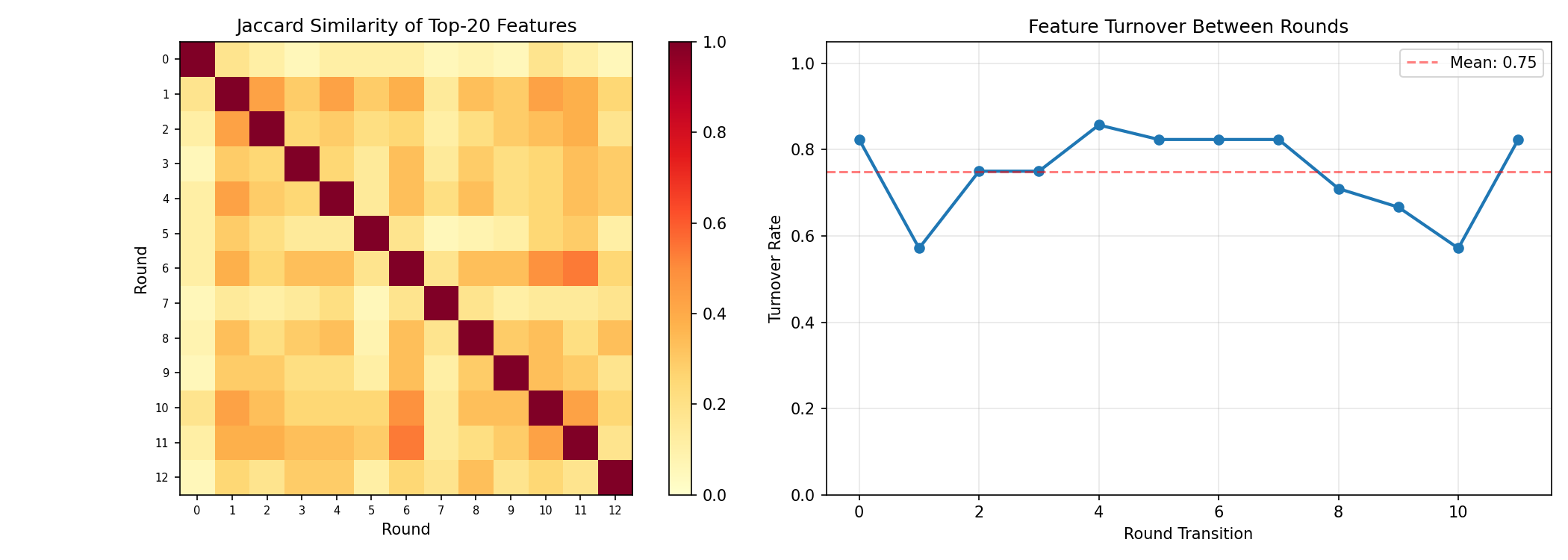
Left: Jaccard similarity of top-20 features between round pairs. Right: 75% mean turnover, but 4 core features persist.
6. Can we causally control the compliance decision?
Yes — but only at layer 16, and only with the right direction.
The logit lens shows the compliance decision manifests at layer 31. But does it originate there? We test this with activation steering: adding a scaled direction vector to the residual stream at different layers during multi-turn jailbreak conversations.
We test three types of direction at multiple layers: the outcome direction (the probe direction for predicting which attacks succeed — category-specific within-category, LOCO AUC 0.60 across categories, so a naive predictive story would not predict strong cross-category causal effects), the intent direction (the probe direction for detecting adversarial conversations, AUC 0.97), the contrastive refusal direction (Arditi et al., 2024), and random directions as controls.
| Direction |
Layer |
Multi-turn ASR |
Δ vs 25% |
| Baseline (no hook) | — | 25% | — |
| Outcome, toward success (+6) | 16 | 36% | +11 pp |
| Outcome, toward failure (−6) | 16 | 24% | −1 pp |
| Intent, toward unsafe (+6) | 16 | 37% | +5 pp |
| Intent, toward safe (−6) | 16 | 19% | −13 pp |
| Random (+6) | 16 | 19% | −6 pp |
| Random (−6) | 16 | 30% | +5 pp |
| Outcome (+6) | 20 | 22% | −3 pp |
| Arditi refusal (±6) | 31 | 26–27% | ±2 pp |
100 JBB goals per condition, 5-turn conversations with trained adversary. JBB standard judge via Together API. Random directions confirm specificity.
Two complementary causal levers at layer 16. The outcome direction is the strongest amplifier of compliance (+11 pp), while the intent direction is the strongest suppressor (−13 pp). These serve different functions: one captures the model's vulnerability to the specific attack, the other captures its general safety posture.
Random directions confirm specificity. Random perturbation at L16 does not produce consistent directional effects (19% and 30% for ±6), ruling out the possibility that any noise at this layer controls safety.
Layer 20 and 31 are causally inert. The outcome direction at layer 20 has no causal effect. The Arditi refusal direction at layer 31 is completely inert. The compliance decision is determined at layer 16 and read out at layer 31 — and the same L16 direction that is only weakly predictive out-of-category is nonetheless the lever that controls behavior.
The picture that emerges
Three claims that have to be held at the same time. First, the victim's residual stream is a strong intent detector (AUC 0.97): "am I being attacked" is a broadly-shared signal the model encodes from its very first layer.
Second, its representation of which attacks will succeed is category-specific and uneven. Within Disinformation, Privacy, Government decision-making, and Malware/Hacking, a linear probe at L16 turn 0 predicts outcome at AUC 0.68–0.85. Within Fraud, Expert advice, Harassment, and Economic harm, it is at chance. And across categories, LOCO AUC is only 0.60. A monitoring pipeline that naively asked "will this conversation result in a jailbreak?" would work on some harm types and fail on others, with no principled way in advance to tell which.
Third, the mechanism is nonetheless real. At layer 16, activation steering on the outcome direction amplifies compliance by +11 pp; steering on the intent direction suppresses it by −13 pp. The standard Arditi refusal direction at layer 31 is inert. The compliance decision is determined at L16 and read out at L31, and the gap between these layers is why output-level safety interventions fail. The probe's predictive power fragments along harm categories; the causal lever at L16 does not.