The Problem: One Policy Per Layout Doesn't Scale
Wake interactions between turbines can reduce wind farm power by up to 40%. Wake steering—intentionally misaligning turbine yaw angles to redirect wakes—offers a promising solution, but determining optimal configurations in real-time is challenging.
Reinforcement learning has shown promise for this control problem, but existing approaches have a critical limitation: they require retraining for each new farm layout. With thousands of wind farms worldwide, each with unique geometry, this is a deployment bottleneck.
We need a policy architecture that can learn transferable wake physics rather than memorizing layout-specific control strategies.
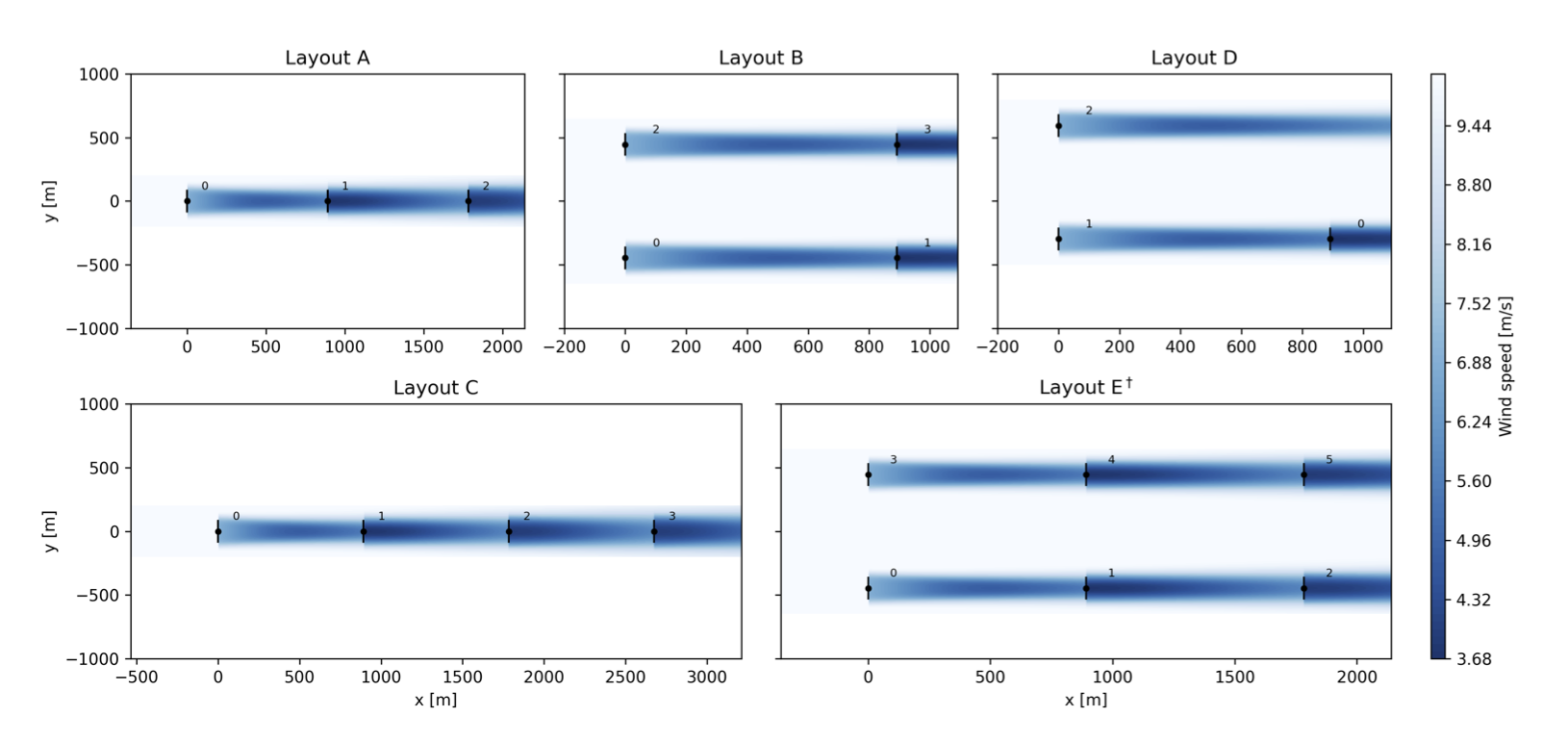
Experimental layouts. Training layouts A–D contain 3–4 turbines with varied geometries: inline arrays (A, C), square grid (B), and triangle (D). Layout E (6 turbines, 3×2 grid) is held out for zero-shot evaluation. Turbine markers colored by local wind speed show wake-induced velocity deficits.
The Solution: Turbines as Tokens
We propose a transformer-based Soft Actor-Critic architecture that treats each turbine as an independent token. The key insight is that wake physics are relational: what matters is not absolute position, but how turbines are positioned relative to each other and to the wind direction.
Per-Turbine Tokenization
Each turbine's observation (wind speed, direction, power, yaw × 15 timesteps) is encoded as a 128-dim token. The same encoder weights are shared across all turbines.
Wind-Relative Positional Encoding
Coordinates are rotated so wind always arrives from a canonical direction (270°). This makes the encoding rotation-invariant: the same farm under different wind directions produces identical positional features.
Relative Position Bias
Pairwise displacements rij = pj - pi are fed through an MLP to compute attention bias, directly encoding spatial relationships like "turbine j is 5D upwind of turbine i."
Attention Masking
Variable farm sizes are handled by padding to Nmax turbines and masking invalid positions. The same network handles 3-turbine and 6-turbine farms.
Architecture
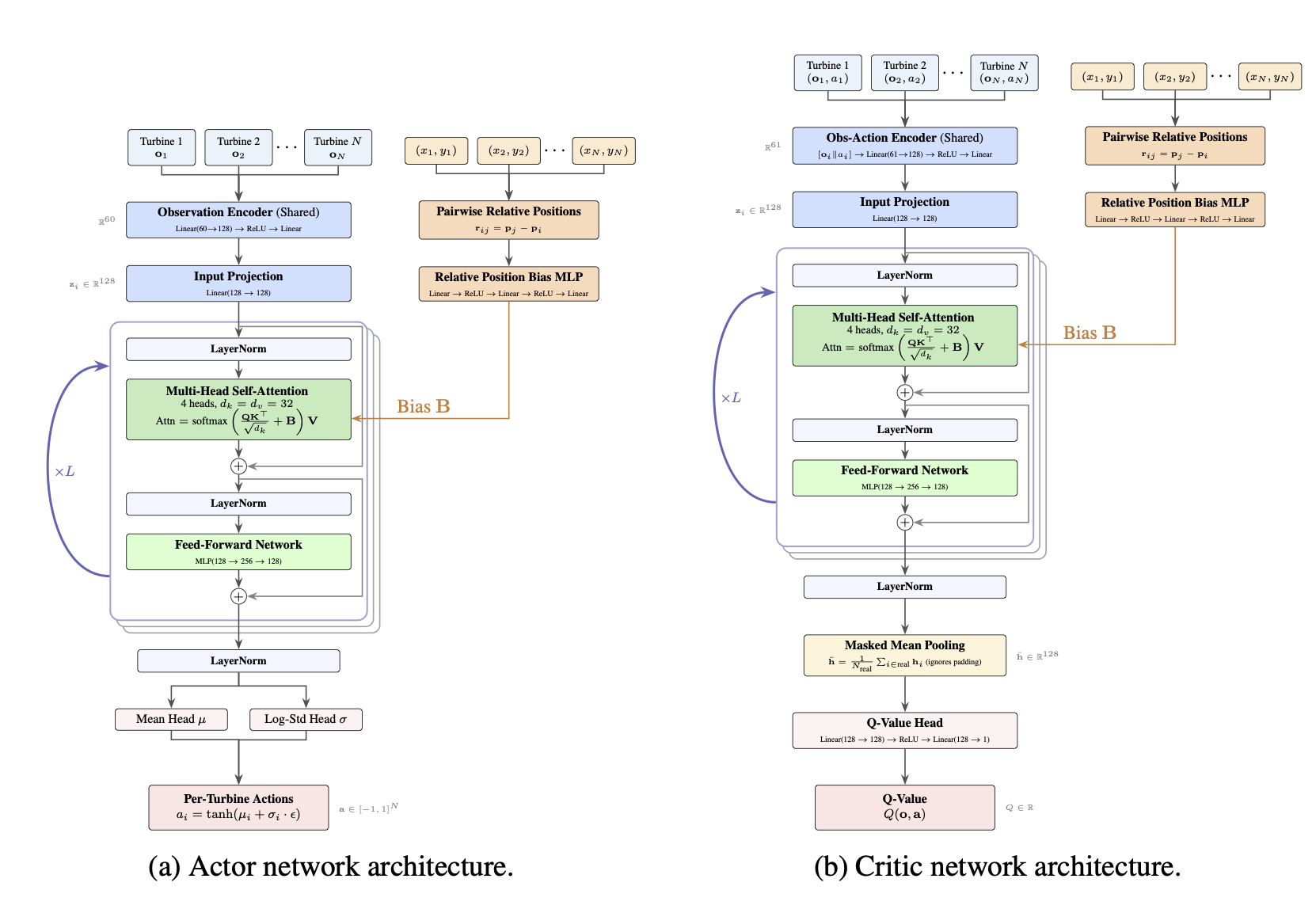
Actor-Critic Architecture. (a) The actor encodes per-turbine observations, applies wind-relative positional bias to attention, and produces yaw rate commands via shared action heads. (b) The critic processes observation-action pairs similarly, then aggregates via masked mean pooling to output a single Q-value.
Key Design Choices
- Permutation equivariance: The same weights applied to each token guarantee that reordering turbine inputs produces correspondingly reordered outputs—forcing the model to learn position-aware control through attention, not index memorization.
- Adaptive target entropy: For variable-size farms, SAC's target entropy scales with actual turbine count: H̄ = −N · da, ensuring appropriate exploration regardless of farm size.
- Shared positional bias: The learned bias b(rij) is computed once and shared across all attention layers, reducing parameters while maintaining expressivity.
Training Protocol: Layout-Randomized Sampling
For multi-layout training, we sample uniformly from layouts {A, B, C, D} at each episode reset. The replay buffer accumulates transitions from all layouts, and minibatches contain mixed-layout samples. This forces the network to learn layout-invariant representations.
Generalist Training
Single policy trained on layouts A–D simultaneously. Receives only 25% of samples from each layout, yet matches specialist performance.
Specialist Baseline
Separate policies trained exclusively on each individual layout. Provides upper bound for layout-specific performance.
Result 1: Negligible Generalization Cost
Despite receiving only 25% of training samples from each layout, the generalist achieves within 0.9% of layout-specific specialists on average.
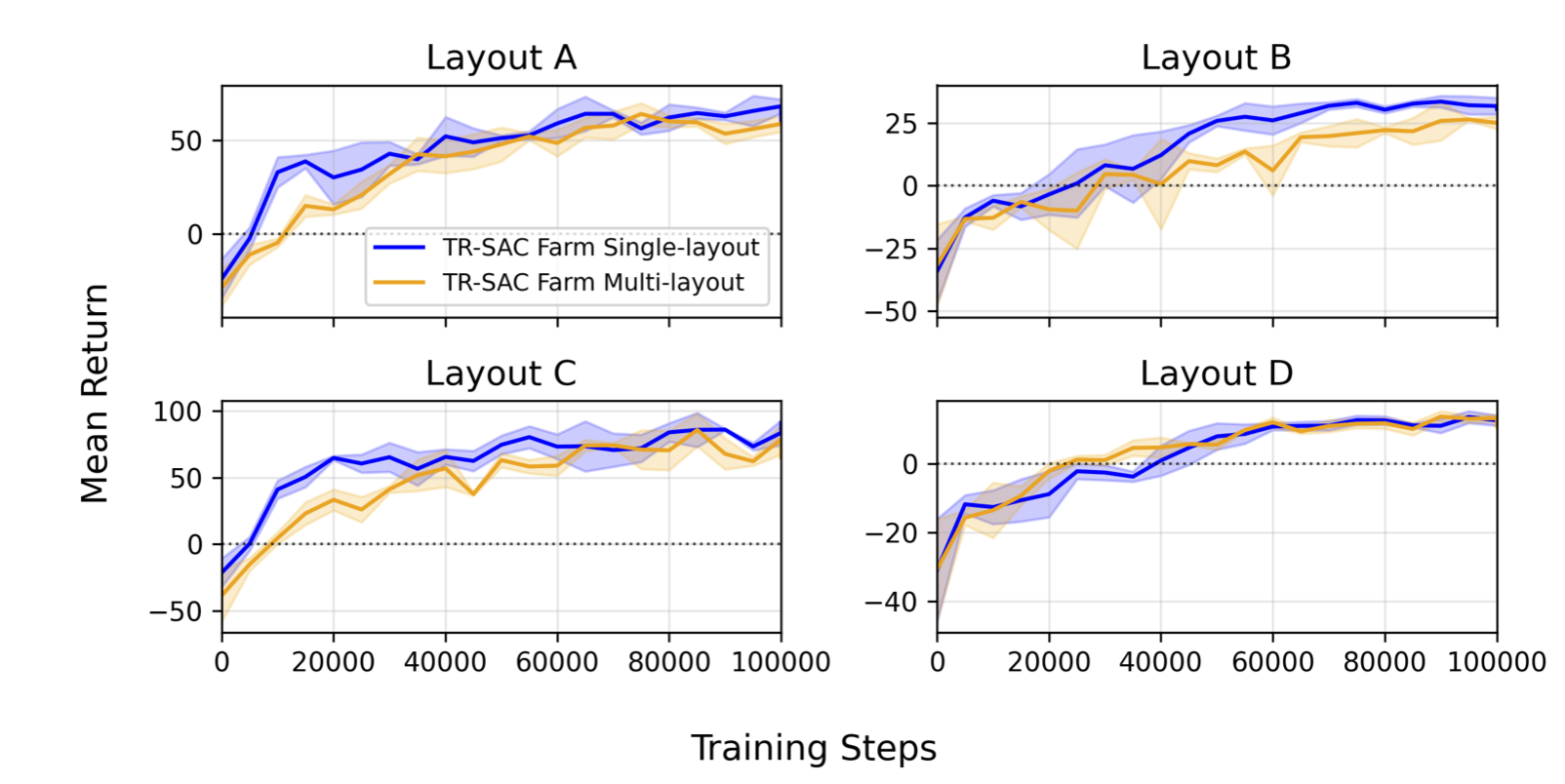
Training convergence. Single-layout specialists (blue) vs. multi-layout generalist (orange) on layouts A–D. The generalist achieves comparable asymptotic performance despite training on four layouts simultaneously.
| Layout | Specialist (MW) | Generalist (MW) | Cost (%) |
|---|---|---|---|
| A (3×1 inline) | 15.60 ± 0.09 | 15.49 ± 0.28 | +0.7% |
| B (2×2 grid) | 22.22 ± 0.14 | 21.60 ± 0.34 | +2.8% |
| C (4×1 inline) | 20.06 ± 0.37 | 19.99 ± 0.16 | +0.4% |
| D (triangle) | 17.89 ± 0.14 | 17.93 ± 0.06 | −0.2% |
| Average | — | — | +0.9% |
Layout D shows negative cost: the generalist slightly outperforms the specialist, suggesting exposure to diverse configurations provides beneficial regularization.
Result 2: Zero-Shot Transfer to Unseen Layouts
The critical test: can the generalist handle a layout it has never seen? Layout E is a 3×2 grid with 6 turbines—more than any training layout—and a novel geometry with complex wake interactions.
Zero-Shot Result:
Without any Layout E training data, the generalist achieves 66.6% of specialist performance. For context, the specialist requires ~30,000 training steps to reach this same level—the generalist gets a substantial head start for free.
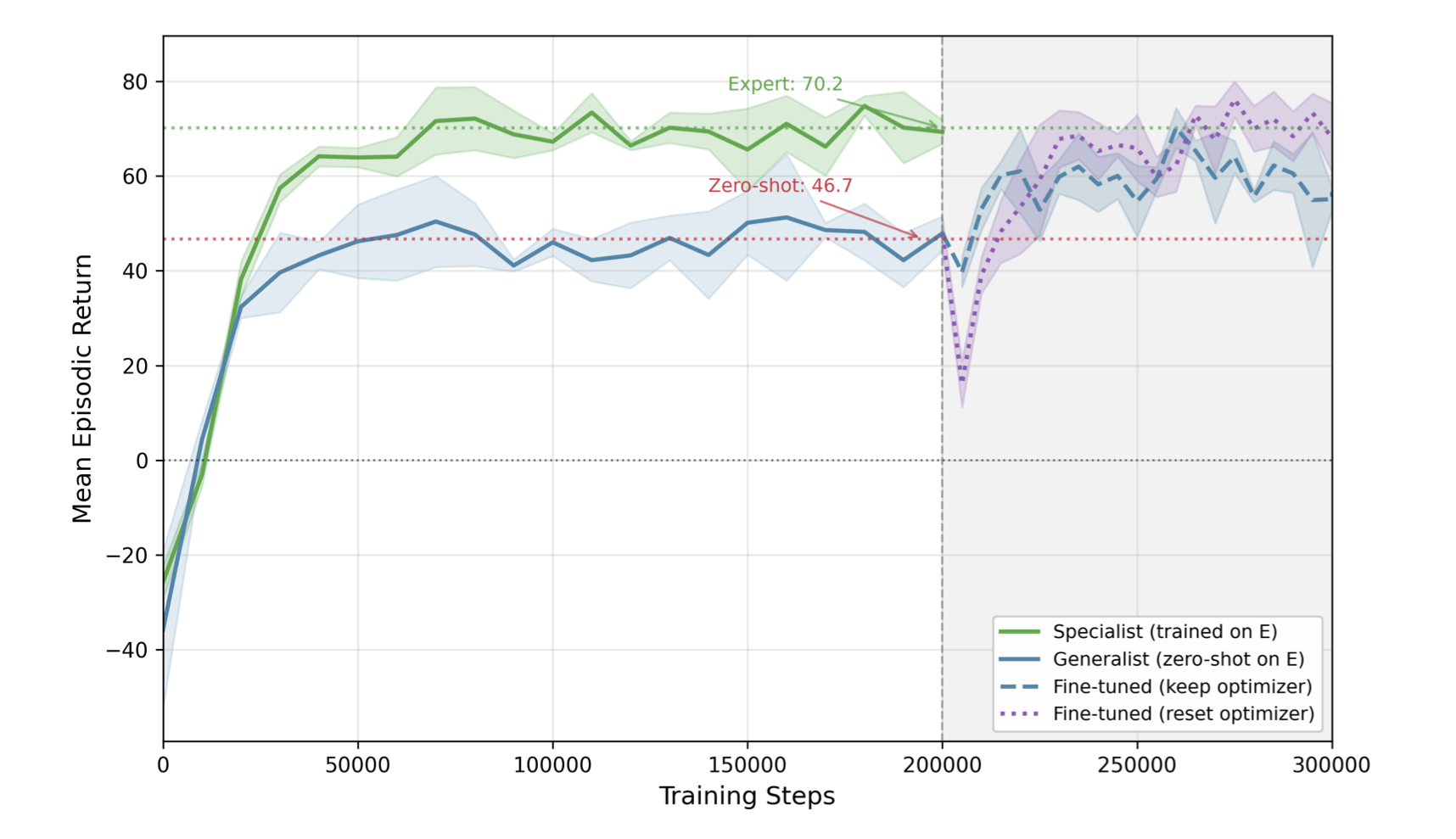
Transfer and adaptation on unseen Layout E. The generalist (orange, flat line) achieves 66.6% of specialist performance zero-shot. Fine-tuning with reset optimizer (purple, dashed) reaches expert level; retaining optimizer state (purple, dotted) yields slower adaptation.
| Model | Mean Return | % of Specialist |
|---|---|---|
| Specialist (trained on E) | 70.16 | 100.0% |
| Generalist (zero-shot) | 46.73 | 66.6% |
| Fine-tuned (keep optimizer) | 56.83 | 81.0% |
| Fine-tuned (reset optimizer) | 70.72 | 100.8% |
Result 3: Efficient Fine-Tuning
For practitioners who want site-specific adaptation, fine-tuning the pre-trained generalist is 2.3× more sample-efficient than training from scratch.
✓ Reset Optimizer State
Fine-tuning reaches 95% of specialist in ~30k steps (vs ~70k from scratch)
Final performance: 100.8% of specialist—slightly exceeds due to regularization benefits from pre-training
✗ Retain Optimizer State
Adam's momentum estimates from multi-layout training cause misdirected updates
Final performance: 81.0% of specialist—plateaus early
Why Resetting Matters
Two factors explain the gap: (1) Adam's momentum estimates reflect a different loss landscape from multi-layout training, and (2) the entropy coefficient α was calibrated for 3–4 turbine layouts (target entropy ≈ −3.5), while Layout E with 6 turbines implies target entropy −6. The mismatched α limits exploration during adaptation.
Why Transformers? Attention Scales Better
On small farms (4 turbines), MLP and Transformer achieve similar performance. But as complexity grows, attention-based spatial reasoning becomes essential.

MLP vs. Transformer on different farm sizes. On 4-turbine Layout B, both architectures converge to similar performance. On 6-turbine Layout E, the transformer achieves returns more than 2× higher than MLP-SAC, suggesting attention mechanisms better capture complex wake interactions.
Relevance to AI Safety & Generalization
While demonstrated on wind farm control, this work addresses fundamental challenges in building AI systems that generalize reliably:
🔄 Out-of-Distribution Generalization
The model generalizes to a layout with more agents than seen during training. It learned transferable physics, not layout-specific memorization—a key property for deploying AI in novel environments.
🧩 Compositional Generalization
Per-turbine tokenization with shared weights forces the model to learn modular, reusable representations. The same "wake interaction" knowledge applies regardless of how many turbines are present.
🎯 Inductive Bias Design
Wind-relative positional encoding embeds domain knowledge (wake physics is directional) directly into the architecture. This is a blueprint for incorporating physical priors into neural networks.
⚡ Sample-Efficient Adaptation
Pre-training on diverse layouts enables 2.3× faster adaptation to new sites. This "foundation model" paradigm—train once broadly, fine-tune cheaply—is increasingly important for safe deployment.
Technical Details
Environment
- Dynamic Wake Meandering model (Dynamiks)
- DTU 10MW reference turbine
- 5D uniform spacing between turbines
- Wind: U∞ = 10 m/s, TI = 7%, θ ∼ U[260°, 280°]
- Control interval: 10s; Episode: ~30-60 min simulated
Architecture
- Embedding dim: 128, Heads: 4, Layers: 2
- Observation: 60-dim per turbine (4 signals × 15 history)
- Action: yaw rate ∈ [−5°, +5°] per step
- Yaw constraint: γ ∈ [−30°, +30°]
- SAC with auto-tuned temperature
Training
Learning Rate
3×10⁻⁴
Batch Size
256
Buffer Size
10⁶
γ / τ
0.99 / 0.005
Practical Deployment Strategy
These results suggest a practical deployment workflow for wind farm operators:
- Train once: Build a generalist policy on diverse representative layouts (one-time cost)
- Deploy zero-shot: For new sites, the generalist provides 66%+ of optimal performance immediately
- Fine-tune briefly: If higher performance is needed, fine-tune with reset optimizer for ~30k steps (2.3× faster than from-scratch)
Open Source
The transformer architecture and training framework are implemented in WindGym. The methodology generalizes to any multi-agent control problem where you need a single policy to handle variable numbers of agents with different spatial configurations.
pip install windgym