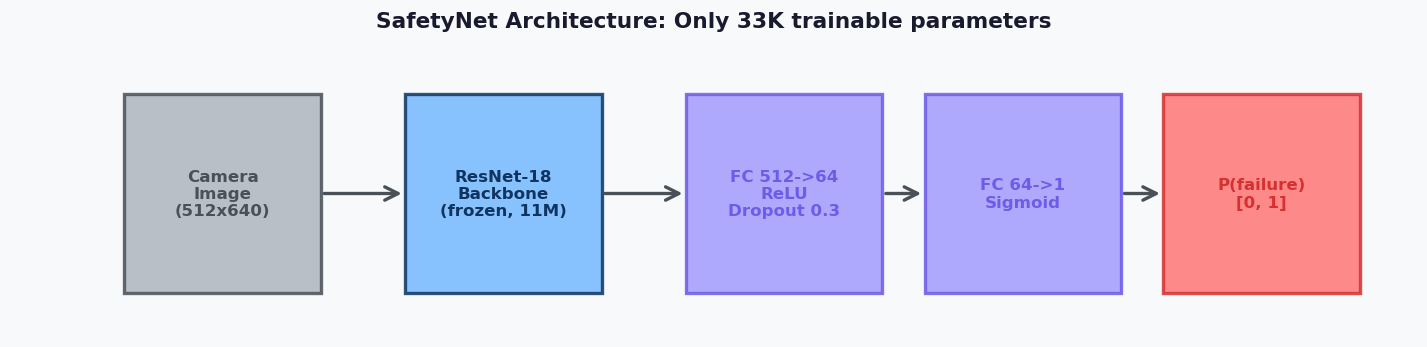
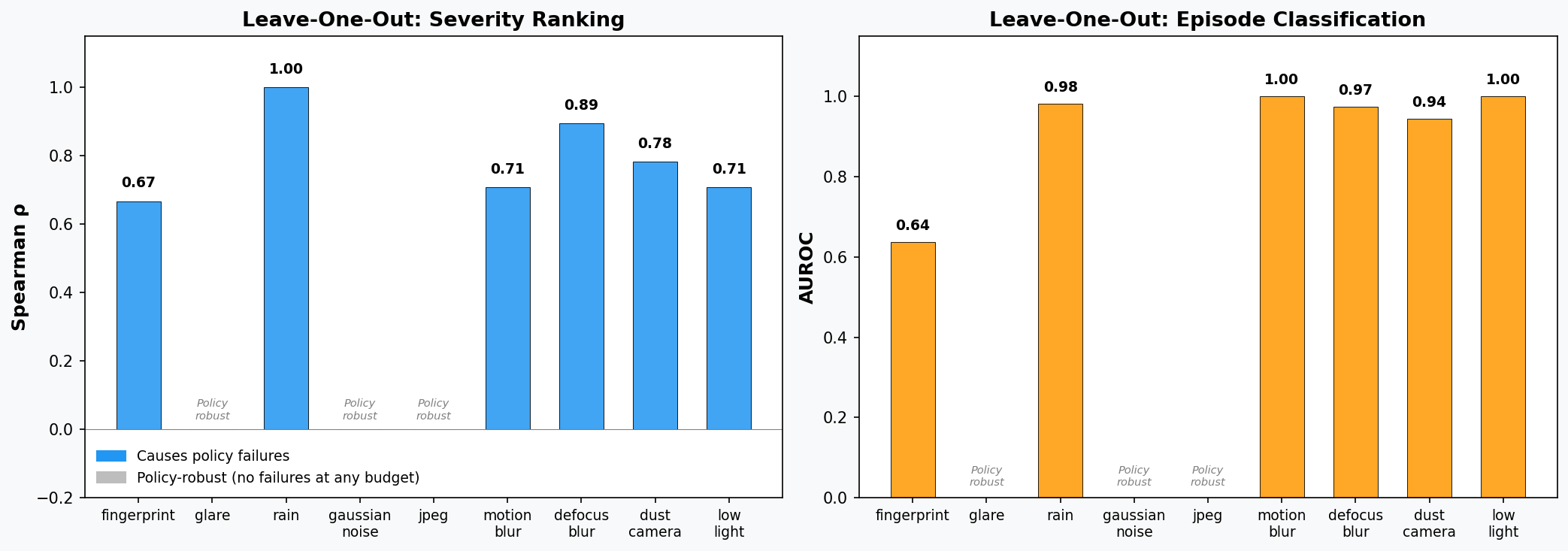
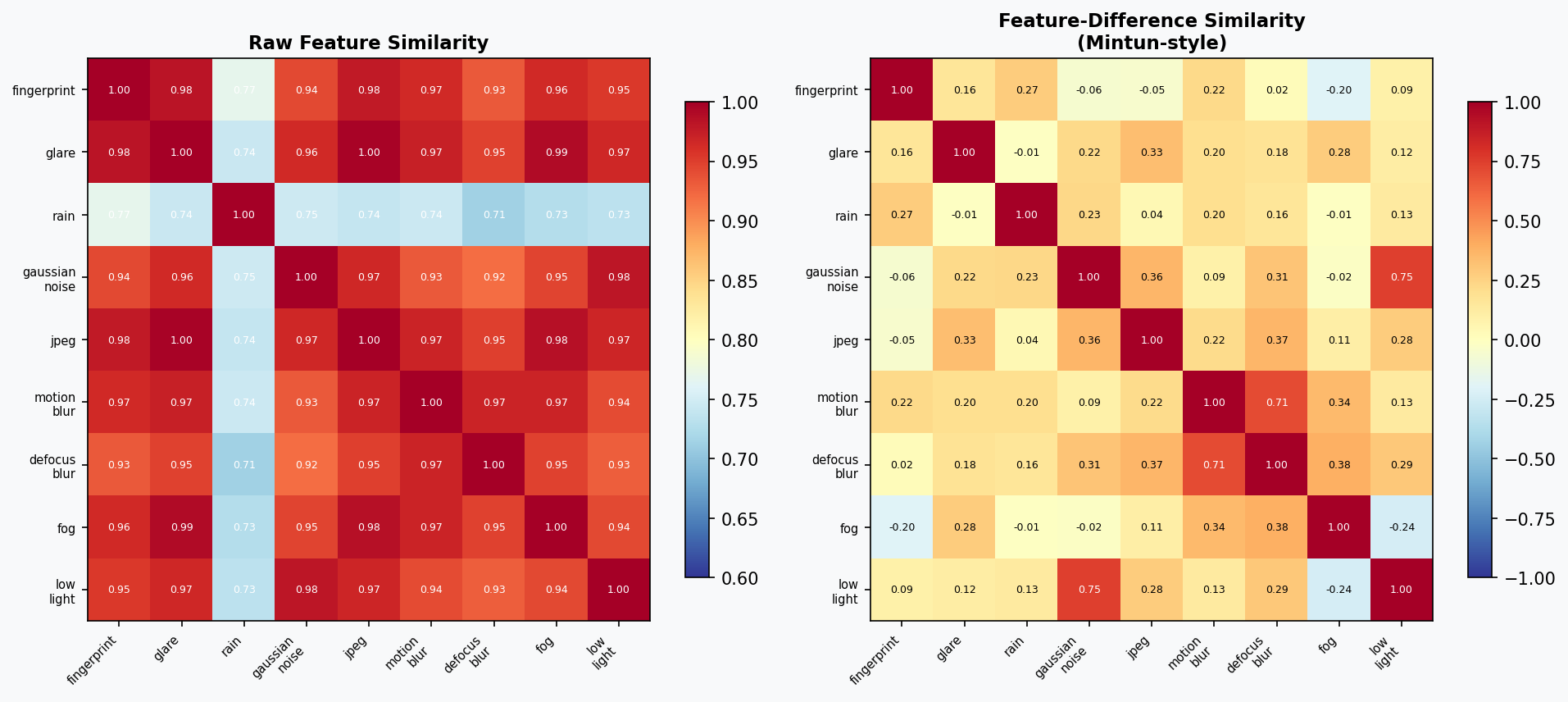
9 Camera Corruption Types
Following the ImageNet-C taxonomy, adapted for fixed-mount robot cameras. Each corruption has a budget level (0–100%) controlling severity.

Each animation shows 10 real episodes where the policy sees the corrupted frames, with a real-time P(failure) gauge and running success counter. The P(failure) predictions come from a model trained without the displayed corruption type.
Clean (100%)
Fingerprint 90% (100%)
Rain 50% (60%)
Glare 90% (100%)
Defocus 90% (60%)
Motion Blur 90% (80%)
Gauss. Noise 90% (100%)
Dust/Mud 90% (80%)
Low-Light 90% (80%)
JPEG 90% (100%)
Format: Type budget (success rate)